CuTe Layout Algebra
Cute Layout Algebra
CuTe는 레이아웃을 다양한 방식으로 결합할 수 있도록 지원하는 "Layout 대수"를 제공한다. 이 대수에는 다음과 같은 연산들이 포함된다.
- Layout 함수형 합성 (Layout functional composition)
- 하나의 레이아웃을 다른 레이아웃에 따라 복제하는 Layout "곱(product)" 개념
- 하나의 레이아웃을 다른 레이아웃에 따라 분할하는 Layout "나눗셈(divide)" 개념
단순한 레이아웃으로부터 복잡한 레이아웃을 구축하기 위한 일반적인 유틸리티들은 Layout 곱에 의존한다. 레이아웃(예: 데이터 레이아웃)을 다른 레이아웃(예: 스레드 레이아웃)에 걸쳐 파티셔닝하기 위한 일반적인 유틸리티들은 Layout 나눗셈에 의존한다. 이러한 모든 유틸리티는 Layout의 함수형 합성을 기반으로 한다.
이 모든걸 관통하는 핵심 관점은 "Layouts are functions from integers to integers."이다.
Coalesce (병합)
coalesce는 (대체로) "연속적으로 합칠 수 있는 모드들을 합쳐서" 더 단순한 레이아웃으로 만든다.
입력 정수값만 고려한다면, Layout을 함수로서 변경하지 않고도 그 형태(shape)와 모드(mode)의 개수를 조작할 수 있다.
coalesce가 유일하게 변경할 수 없는 것은 Layout의 size이다.
a = cute.make_layout((2, (1, 6)), stride=(1, (6, 2)))
result = cute.coalesce(a) # result: 12:1
여기서 결과의 모드(mode) 수가 더 적고 "더 단순함"을 확인할 수 있다. 실제로 이는 (동적으로 수행되는 경우) 좌표 매핑 및 인덱스 매핑에서 몇 가지 연산을 절약할 수 있게 해준다.
coalesce의 조건
병합 조건: 두 모드가 합쳐지려면 앞 모드의 (
shape×stride) = 뒷 모드의stride여야 한다. 즉, 앞 모드가 끝나는 지점에서 뒷 모드가 바로 이어져야 연속성이 보장된다. column-majorLayout이 해당 조건을 만족할 수 있다.무시 조건: size가 1인 모드는 stride에 관계없이 무시된다.
레이아웃의 모드들을 "병합(coalesce)"하기 위해, 어떤 레이아웃이든 평탄화(flatten)한 후 인접한 각 모드 쌍에 대해 위의 이항 연산을 적용할 수 있다.
위의 예제에서 모드 1-0의 크기가 1이므로 무시되고 남은 Layout은 (2,6):(1,2)로 모드 0의 (shape × stride) = 모드 1의 stride를 만족한다.
따라서 병합되어 12:1로 결과가 나온다.
by-mode coalesce (모드별 병합)
결과 랭크(예: 2-D 유지) 같은 걸 유지하고 싶을 때 target_profile을 받는다.
result2 = cute.coalesce(layout, target_profile=(1,2)) # result2: (2,6):(1,2)
result3 = cute.coalesce(layout, target_profile=(1,(2,3))) # result3: (2,(1,6)):(1,(0,2))
result4 = cute.coalesce(layout, target_profile=(1,)) # result4: (2,(1,6)):(1,(6,2))
result5 = cute.coalesce(layout, target_profile=(1,1)) # result5: (2,6):(1,2)
target_profile 안의 값은 어떤 정수 값이든 상관없고, 튜플의 길이가 원본 구조와 일치해야 coalesce가 작동한다.
Composition (합성)
composition(A, B)는 B로 좌표를 인덱스로 변환하고, 그 인덱스를 A의 좌표로 사용해서 최종 인덱스를 얻는다.
Functional composition, R := A ∘ B
R(c) := (A ∘ B)(c) := A(B(c))
A = (6,2):(8,2), B = (4,3):(3,1)로 예를 들어보면, 다음과 같이 composition 된다.
R( 0) = A(B( 0)) = A(B(0,0)) = A( 0) = A(0,0) = 0
R( 1) = A(B( 1)) = A(B(1,0)) = A( 3) = A(3,0) = 24
R( 2) = A(B( 2)) = A(B(2,0)) = A( 6) = A(0,1) = 2
R( 3) = A(B( 3)) = A(B(3,0)) = A( 9) = A(3,1) = 26
R( 4) = A(B( 4)) = A(B(0,1)) = A( 1) = A(1,0) = 8
R( 5) = A(B( 5)) = A(B(1,1)) = A( 4) = A(4,0) = 32
R( 6) = A(B( 6)) = A(B(2,1)) = A( 7) = A(1,1) = 10
R( 7) = A(B( 7)) = A(B(3,1)) = A(10) = A(4,1) = 34
R( 8) = A(B( 8)) = A(B(0,2)) = A( 2) = A(2,0) = 16
R( 9) = A(B( 9)) = A(B(1,2)) = A( 5) = A(5,0) = 40
R(10) = A(B(10)) = A(B(2,2)) = A( 8) = A(2,1) = 18
R(11) = A(B(11)) = A(B(3,2)) = A(11) = A(5,1) = 42
놀라운 관찰은 위에서 정의된 R(c) = k 함수가 또 다른 Layout으로 작성될 수 있다는 것이다.
위에서 R = ((2,2),3):((24,2), 8)로 표현할 수 있다.
그리고 B와 R은 compatible하다. 즉, B의 모든 좌표는 R의 좌표로서도 사용될 수 있다. 이는 B가 R의 정의역을 정의하기 때문에 함수 합성의 예상되는 속성이다.
Composition을 "레이아웃 변형"으로 이해해보자. A가 "메모리에서의 실제 접근 패턴", B가 "좌표를 어떤 방식으로 재배열/재해석할지" 라고 보면, A ∘ B는 "좌표계를 먼저 B로 바꾼 다음 그 좌표를 A로 메모리 인덱스로 바꾸는 것"이 된다.
즉, reshape/transpose/tile 같은 작업을 데이터 이동 없이 표현할 수 있는 수단이 된다.
Computing Composition (컴포지션 계산)
몇가지 관찰사항이 있다.
B = (B_0, B_1, ...). 레이아웃은 그 하위 레이아웃들을 연결한 것으로 표현될 수 있습니다.A o B = A o (B_0, B_1, ...) = (A o B_0, A o B_1, ...). B가 단사(injective)인 경우, 합성(composition)은 연접(concatenation)과 왼쪽 분배(left-distributive) 법칙을 따른다.
위 내용을 통해 일반성을 잃지 않고 B = s:d를 integral shape와 integral stride를 가진 레이아웃(layout)으로 가정할 수 있다.
아무리 복잡한 구조여도 재귀적으로 쪼개다보면 결국 가장 작은 단위인 s:d 형태로 떨어지게 된다.
또한 A를 평탄화(flattened)되고 병합(coalesced)된 레이아웃으로 가정할 수도 있다.
A o B = coalesce(A) o B이기 때문에, 분석할 때 A가 이미 가장 단순한 형태라고 가정해도 된다.
먼저 A가 정수형일 때 A = a:b라고 하면,
A = a:b → 좌표 i에 대해 A(i) = i * b
B = s:d → 좌표 i에 대해 B(i) = i * d
R(i) = A(B(i)) = A(i * d) = (i * d) * b = i * (b * d)
따라서 R = A o B = a:b o s:d = s:(b*d)이다.
여기서 합성 R의 결과는 A의 처음 s개 요소들을 d stride로 건너뛰며 가져온 것이다.
다음 A가 다중 모드인 경우를 보자. 정수 s와 d에 대해 A o B = A o s:d는 다음과 같은 작업을 원한다.
1단계: d번째 요소마다 A의 요소를 생성하는 중간 레이아웃을 결정한다. (stride 처리)
이 중간 레이아웃의 형태는 A의 형태에서 왼쪽부터 시작하여 첫 번째 d 요소를 점진적으로 "나누어 빼내어" 계산할 수 있다.
(6,2) / 2 => (3,2)
(6,2) / 3 => (2,2)
(6,2) / 6 => (1,2)
(6,2) / 12 => (1,1)
(3,6,2,8) / 3 => (1,6,2,8)
(3,6,2,8) / 6 => (1,3,2,8)
(3,6,2,8) / 9 => (1,2,2,8) <-
(3,6,2,8) / 72 => (1,1,1,4) # 24 남음, 4 남음, 2 남음
중간 레이아웃(stride layout)의 스트라이드를 계산하기 위해, 위 연산의 나머지를 사용하여 A의 스트라이드 크기를 조정한다.
예를 들어, 스트라이드 (w,x,y,z)를 가진 마지막 예제 (3,6,2,8):(w,x,y,z) / 72는 스트라이드 레이아웃의 스트라이드로 (72*w,24*x,4*x,2*z)을 생성한다.
B의 stride d가 A의 shape를 "깔끔하게" 나눌 수 있어야 한다. 스트라이드 가분성 조건(stride divisibility condition)이라고 한다.
2단계: 중간 레이아웃에서 첫 번째 s개 요소만 취하여, 결과가 B와 호환되는 shape를 갖도록 한다. (shape 처리)
이것은 왼쪽에서 시작하여 중간 레이아웃의 shape에서 s개를 "남기고 나머지를 제거"함으로써 계산할 수 있다.
(6,2) % 2 => (2,1)
(6,2) % 3 => (3,1)
(6,2) % 6 => (6,1)
(6,2) % 12 => (6,2)
(3,6,2,8) % 6 => (3,2,1,1)
(3,6,2,8) % 9 => (3,3,1,1)
(1,2,2,8) % 2 => (1,2,1,1)
(1,2,2,8) % 16 => (1,2,2,4) <-
이 작업은 결과가 B와 호환되는 형태를 갖도록 한다. 이 연산은 합리적인 결과를 얻기 위해 형태 가분성 조건(shape divisibility condition)을 만족해야 하며, 가능한 경우 CuTe에서 정적으로 검사된다.
위의 예제들로부터 (3,6,2,8):(w,x,y,z) o 16:9 = (1,2,2,4):(9*w,3*x,y,z) 합성을 구성할 수 있다.
Shape와 stride가 컴파일 타임 상수면, CuTe가 컴파일 시점에 가분성을 체크해서 잘못된 composition을 막아준다고 한다.
By-mode Composition (모드별 합성)
모드별 coalesce와 마찬가지로, 때로는 A 레이아웃의 shape를 유지하면서 개별 모드에 composition을 적용하고 싶을 때가 있다.
예를 들어, 2차원 Layout이 있을 때, 열(column) 방향으로 일부 요소만 선택한 sublayout과 행(row) 방향으로 일부 요소만 선택한 sublayout을 따로 만들고 싶은 경우다.
이를 위해 composition의 두 번째 인자 B로 Tiler를 사용할 수 있다.
Tiler는 레이아웃 하나, 또는 레이아웃들의 튜플이다 (IntTuple의 일반화).
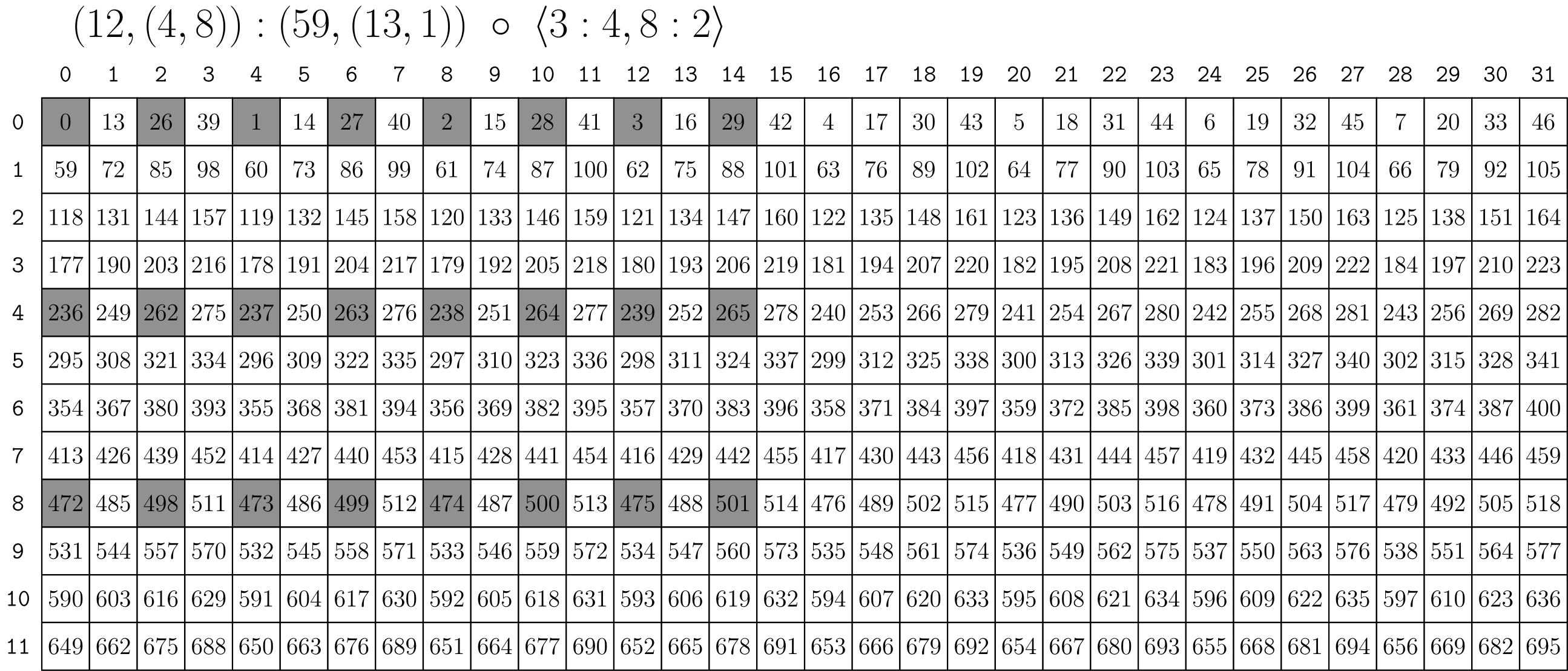
a = cute.make_layout((12, (4, 8)), stride=(59, (13, 1))) # (12,(4,8)):(59,(13,1))
tiler = (cute.make_layout((3, 4)), cute.make_layout((8, 2))) # <3:4, 8:2>
r = cute.composition(a, tiler) # (3,(2,4)):(236,(26,1))
r2 = cute.composition(a[0], tiler[0]) # 3:236
r3 = cute.composition(a[1], tiler[1]) # (2,4):(26,1)
same_r = cute.make_layout((r2.shape, r3.shape), stride=(r2.stride, r3.stride)) # (3,(2,4)):(236,(26,1))
위 코드의 result 는 아래 그림에서 강조 표시된 원본 레이아웃의 3x8 하위 레이아웃으로 표현될 수 있다.
하위 레이아웃 연결 표기법 (LayoutA, LayoutB, ...) 과 Tiler를 구분하기 위해 종종
편의를 위해 CuTe는 Shape를 타일러로도 해석한다. Shape는 스트라이드 1을 가진 레이아웃 튜플로 해석된다.
a = cute.make_layout((12,(4,8)), stride= (59,(13,1))) # (12,(4,8)):(59,(13,1))
tiler = (3, 8) # <3:1, 8:1>과 동등
result = cute.composition(a, tiler) # (3,(4,2)):(59,(13,1))
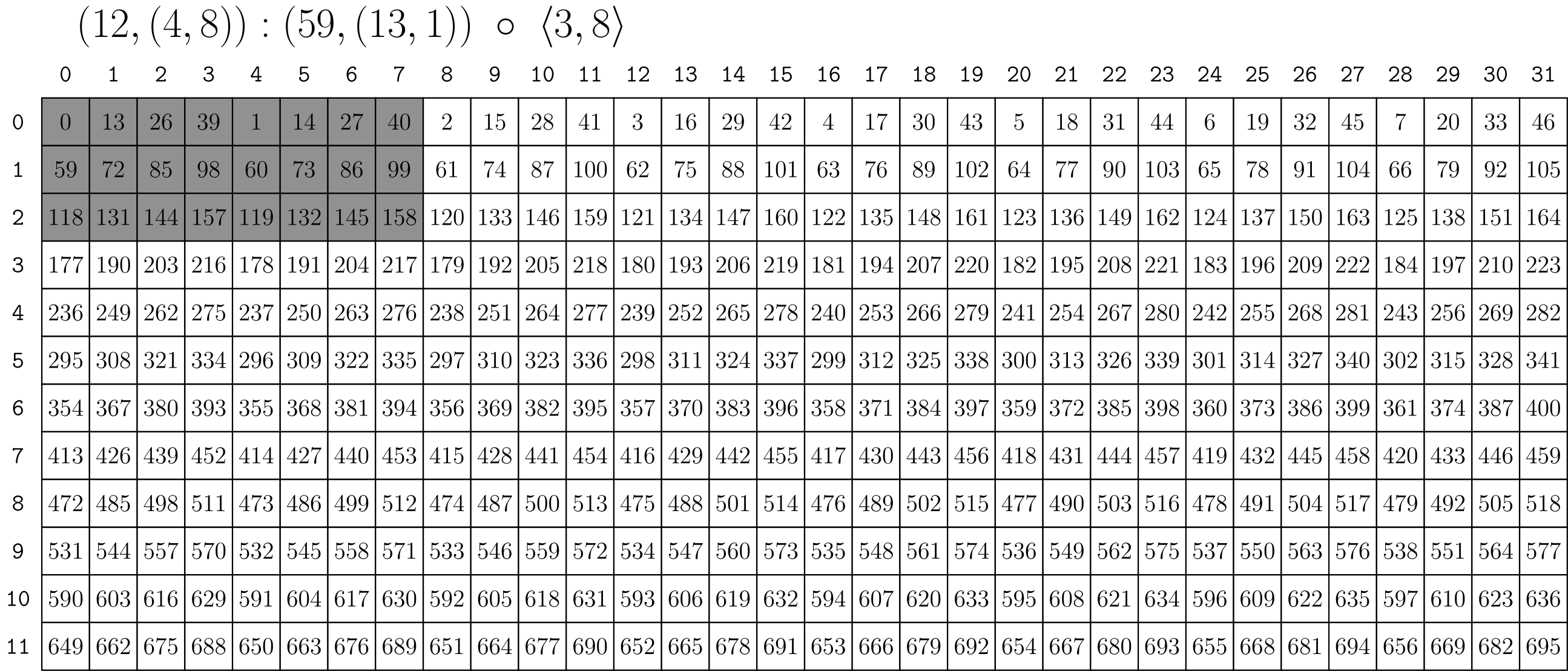
이를 통해 합성이 모드별로 적용되어 텐서의 지정된 모드의 임의의 서브레이아웃을 검색할 수 있다("이 MxNxL 텐서의 3x5x8 서브블록을 주세요"). 또한 데이터의 전체 타일을 1차원 벡터인 것처럼 재형성 및 재정렬할 수 있다("이 8x16 데이터 블록을 이 이상한 요소 순서를 사용하여 32x4 블록으로 재정렬하세요"). 모드별 합성의 경우는 스레드 블록을 타일링할 때 자주 나타난다. 1차원 재형성 및 재정렬은 MMA의 스레드와 값에 임의의 분할 패턴을 적용하고자 할 때 나타날 것이다.
Complement (보수, 보완)
composition이 레이아웃 A에서 특정 좌표를 "선택"한다면, 선택되지 않은 나머지는 어떻게 표현할까? complement가 바로 이 역할을 한다. 일반적인 타일링을 구현하기 위해서는 임의의 요소들(타일)을 선택하고, 그 타일들의 레이아웃(남은 부분 또는 "나머지")을 설명할 수 있어야 한다.
A를 선택된 요소들, M을 전체 공간이라고 하면 R = complement(A, M)은 A를 선택하지 않은 나머지 요소들을 나타낸다.
그리고 R은 다음과 같은 특성을 만족한다.
size(R) ≤ size(M). 즉, 전체 크기를 넘지 않는다.R의 스트라이드는 양수이며 증가한다. 즉,R은 정렬되어 있다. 이는R이 고유함을 의미한다.A와R은 서로소인 공역을 가진다. 즉,A와R은 겹치지 않는다.
Complement Example
complement(4:1, 24)는6:4이다.(4,6):(1,4)는 코사이즈(cosize) 24를 갖는다. 레이아웃4:1은6:4와 함께 6번 반복된다.complement(6:4, 24)는4:1이다.(6,4):(4,1)는 코사이즈(cosize) 24를 갖는다.6:4의 "구멍(hole)"은4:1로 채워진다.complement((4,6):(1,4), 24)는1:0이다.complement(4:2, 24)는(2,3):(1,8)이다.(4,(2,3)):(2,(1,8))의 코사이즈는 24를 갖는다.4:2의 "구멍"은2:1로 먼저 채워진 다음,3:8로 3번 반복된다.complement((2,4):(1,6), 24)는3:2이다.((2,4),3):((1,6),2)의 코사이즈는 24이며 고유 인덱스를 생성한다.complement((2,2):(1,6), 24)는(3,2):(2,12)이다.((2,2),(3,2)):((1,6),(2,12))의 코사이즈는 24이며 고유 인덱스를 생성한다.

시각적으로 볼 때, 위 그림은 마지막 예시의 공역을 나타낸다. 원래 레이아웃 (2,2):(1,6)은 회색으로 표시되어 있다. complement는 원래 레이아웃(다른 색상으로 표시)을 "반복"하여 결과의 공역 크기가 24가 되게 한다. complement의 결과 layout인 (3,2):(2,12)은 "반복의 레이아웃"으로 볼 수 있다.
Divide (Tiling)
이제, 하나의 Layout을 다른 Layout으로 나누는 연산을 정의할 수 있다.
레이아웃을 여러 구성 요소로 나누는 함수는 레이아웃의 타일링(tiling) 및 파티셔닝(partitioning)을 위한 토대로 유용하다.
이 섹션에서는 모든 Layout을 정수에서 정수로 가는 1차원 함수로 간주하는 logical_divide(Layout, Layout)를 정의하고, 해당 정의를 사용하여 다차원 Layout 분할을 생성할 것이다.
logical_divide(A, B)는 레이아웃 A를 두 개의 모드로 나눈다.
첫 번째 모드에는 B가 가리키는 모든 요소가 포함되고, 두 번째 모드에는 B가 가리키지 않는 모든 요소가 포함된다.
형식적으로는 다음과 같이 표현된다.
그리고 다음과 같이 구현된다.
def logical_divide(layout, tiler):
complement_tiler = cute.complement(tiler, cute.size(layout))
tiler_layout = cute.make_layout(
(tiler.shape, complement_tiler.shape),
stride=(tiler.stride, complement_tiler.stride),
)
return cute.composition(layout, tiler_layout);
오직 연결(concatenation), 합성(composition), 보수(complement)의 관점에서만 정의된다.
논리적 분할 1차원 예시
1차원 레이아웃 A = (4,2,3):(2,1,8)을 타일러 B = 4:2로 타일링하는 경우를 생각해 보자.
이는 A 에 의해 정의된 특정 저장 순서로 배치된 24개 요소의 1차원 벡터가 있고, 여기서 2의 스트라이드(stride)를 가진 4개 요소의 타일을 추출하려는 것을 의미한다.
이는 위 구현 섹션에서 설명한 세 단계에 따라 계산된다.
size(A) = 24에 대한B = 4:2의 보수(Complement)는B* = (2,3):(1,8)이다.B와B*를 연결하여B_layout = (4,(2,3)):(2,(1,8))을 생성한다.A와B_layout의 합성(Composition)은((2,2),(2,3)):((4,1),(2,8))이다.
마지막 합성 과정의 왼쪽을 계산해보자.
`A = (4,2,3):(2,1,8)`과 `B = 4:2`의 합성은 먼저 `stride=2` 나눗셈을 통해 `(2,2,3):(4,1,8)`을 얻는다.
그리고 `shape=4`를 맞추기 위해 `(2,2,1):(4,1,8)`을 얻는다.
coalsceing을 적용하여 `(2,2,1):(4,1,8)`을 `(2,2):(4,1)`으로 변환한다.
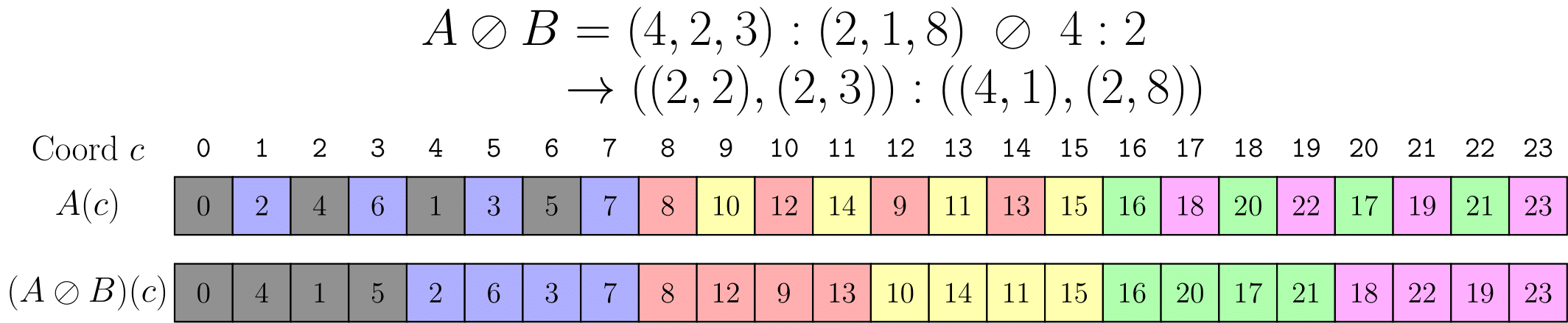
위 그림은 A를 1차원 레이아웃으로 묘사하며, B가 가리키는 요소들은 회색으로 강조되어 있다.
레이아웃 B는 데이터의 "타일"을 설명하며, A에는 각 색상으로 표시된 여섯 개의 타일이 존재한다.
분할 후, 결과의 첫 번째 모드는 데이터 타일이며 두 번째 모드는 각 타일을 순회한다.
논리적 분할 2D 예시
2D 레이아웃 A = (9,(4,8)):(59,(13,1))이 있고 열 방향(모드-0)으로 3:3를, 행 방향(모드-1)으로 (2,4):(1,8)를 적용하려 한다.
이는 타일러(tiler)를 B = <3:3, (2,4):(1,8)>과 같이 작성할 수 있음을 의미한다.

위 그림은 A를 2D 레이아웃으로 묘사하며, B가 가리키는 요소들을 회색으로 강조되어 있다.
레이아웃 B는 데이터의 "타일"을 설명하며, A에는 각 색상으로 표시된 12개의 타일이 존재한다.
분할 후, 결과의 각 모드 중 첫 번째 모드는 데이터 타일이 되고, 각 모드의 두 번째 모드는 각 타일을 순회한다.
이러한 관점에서 이 연산은 흩어져 있던 같은 타일의 원소들이 연속된 좌표로 모이기 때문에 일종의 gather 연산 또는 단순히 행과 열에 대한 순열로 볼 수 있다.
Zipped, Tiled, Flat Divides
어떤 형상(shape)의 Layout과 Tiler가 있다고 가정할 때, 각 연산은 logical_divide를 적용하지만 잠재적으로 모드들을 더 편리한 형태로 재배열 한다.
Layout Shape : (M, N, L, ...)
Tiler Shape : <TileM, TileN>
logical_divide : ((TileM,RestM), (TileN,RestN), L, ...)
zipped_divide : ((TileM,TileN), (RestM,RestN,L,...))
tiled_divide : ((TileM,TileN), RestM, RestN, L, ...)
flat_divide : (TileM, TileN, RestM, RestN, L, ...)
Product (Tiling)
마지막으로, 레이아웃과 다른 레이아웃의 곱을 정의할 수 있다.
이 섹션에서는 모든 Layout을 정수에서 정수로의 1차원 함수로 간주하는 logical_product(Layout, Layout)를 정의한 다음, 해당 정의를 사용하여 다차원 Layout 곱을 생성할 것이다.
logical_product(A, B)는 두 개의 모드를 가진 레이아웃을 결과로 내놓으며, 여기서 첫 번째 모드는 레이아웃 A이고 두 번째 모드는 레이아웃 B이지만 각 요소가 레이아웃 A의 "고유한 복제"로 대체된 형태이다.
형식적으로는 다음과 같이 표현된다.
그리고 다음과 같이 구현된다.
def logical_product(layout, tiler):
complement_layout = cute.complement(layout, cute.size(layout)*cute.cosize(tiler))
composition_layout = cute.composition(complement_layout, tiler)
return cute.make_layout(
(layout.shape, composition_layout.shape),
stride=(layout.stride, composition_layout.stride)
)
마찬가지로 오직 연결(concatenation), 합성(composition), 보수(complement)의 관점에서만 정의된다.
논리적 곱 1차원 예시
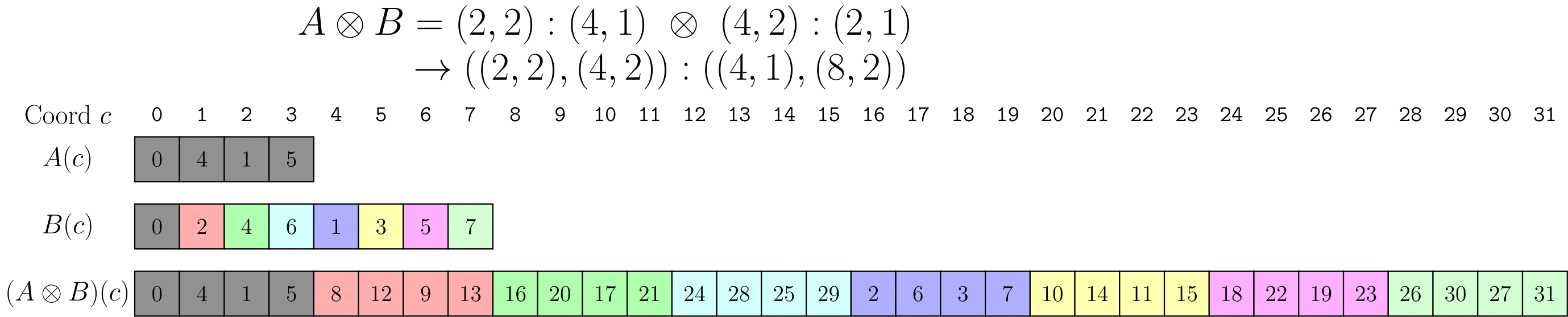
B = 6:1 에 따라 1D 레이아웃 A = (2,2):(4,1)을 재현해보자.
이는 A로 정의된 4개 요소의 1D 레이아웃이 있고 이를 6번 재현하려는 것을 의미한다.
cosize(B)=6,size(A)=4이므로 24에 대한 A의 complement는A* = (2,3):(2,8)이다.A*과B의 Composition은(2,3):(2,8)이다.- concatenation을 통해
(2,2):(4,1)과(2,3):(2,8)을 연결하여((2,2),(2,3)):((4,1),(2,8))을 얻는다.
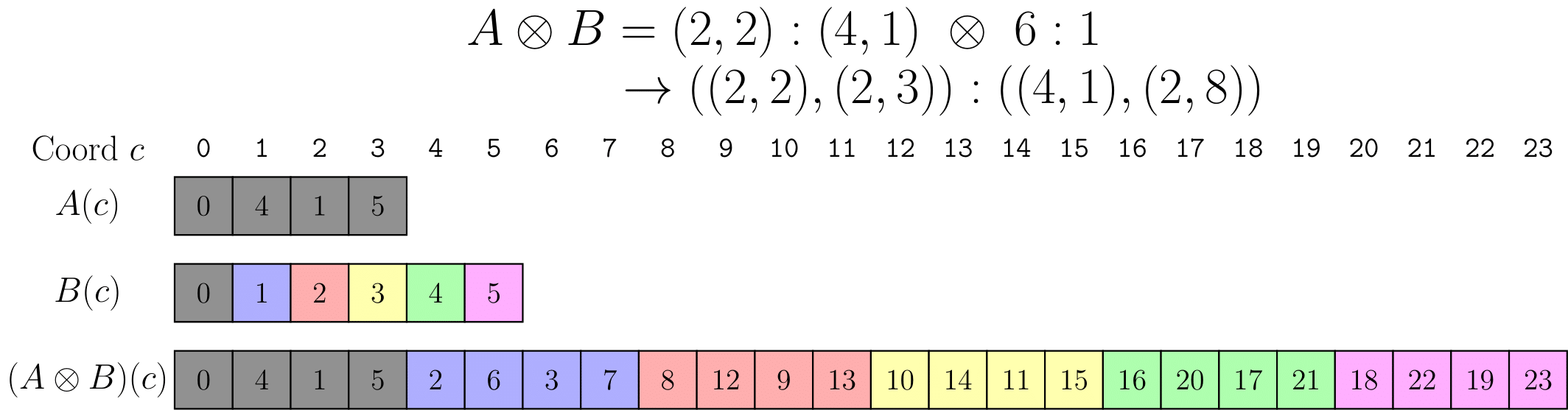
위 그림은 레이아웃 A와 B를 1차원 레이아웃으로 묘사한다. 레이아웃 B는 A가 반복되는 횟수와 순서를 설명하며, 명확성을 위해 색상이 지정되었다. 곱셈 연산 후, 결과의 첫 번째 모드는 데이터의 타일이 되고, 결과의 두 번째 모드는 각 타일을 반복한다.
B를 변경함으로써 곱셈 결과 내 타일의 수와 순서를 바꿀 수 있다.
B를 (4,2):(2,1)로 변경하면 다음과 같이 된다.
논리적 곱 2차원 예시
divide와 마찬가지로 tiler 모드별 전략을 사용하여 다차원 곱을 작성할 수도 있다.
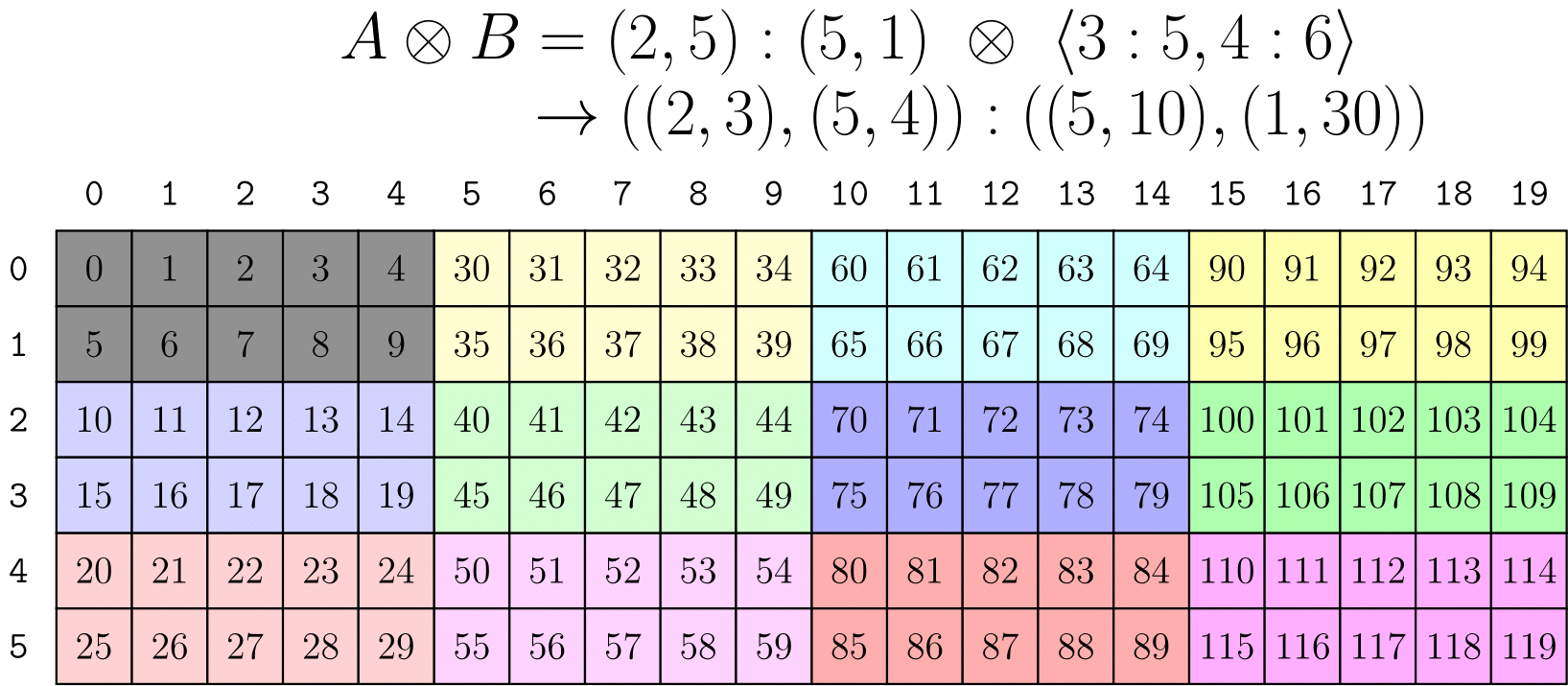
위 이미지는 tiler를 사용하여 logical_product를 모드별로 적용하는 방법을 보여준다.
이것이 권장되는 방식은 아니지만, 결과는 2x5 행 우선(row-major) 블록이 3x4 열 우선(column-major) 배열로 타일링된 랭크-2 레이아웃이 된다.
이 방식이 권장되지 않는 이유는 위 식의 tiler B가 매우 직관적이지 않기 때문이다.
실제로 이를 구성하려면 A의 shape와 stride에 대한 완벽한 정보가 필요하다.
우리는 A와 B를 독립적으로 유지하면서 훨씬 더 직관적인 방식으로 "레이아웃 B에 따라 레이아웃 A를 타일링하라"는 표현을 구현하고자 한다.
Blocked 및 Raked 곱
blocked_product(LayoutA, LayoutB)와 raked_product(LayoutA, LayoutB)는 1차원 logical_product를 기반으로 하는 랭크 민감형(rank-sensitive) 변환으로, 우리가 가장 자주 표현하고자 하는 직관적인 Layout 곱을 표현할 수 있게 해준다.
이러한 함수들을 구현할 때 핵심적인 관찰 사항은 logical_product 의 호환성 사후 조건(post-conditions)이다.
// @post rank(result) == 2
// @post compatible(layout_a, layout<0>(result))
// @post compatible(layout_b, layout<1>(result))
A는 항상 결과의 0번 모드와 호환되고 B는 항상 결과의 1번 모드와 호환되기 때문에, 만약 A와 B를 동일한 랭크로 만든다면 곱 연산 이후에 유사한 모드들끼리 "재결합(reassociate)"할 수 있다.
즉, A의 "열(column)" 모드를 B의 "열" 모드와 결합할 수 있고, A의 "행(row)" 모드를 B의 "행" 모드와 결합할 수 있는 식입니다.
이것이 바로 blocked_product와 raked_product가 수행하는 작업이며, 이들을 랭크 민감형(rank-sensitive)이라고 부르는 이유이다.
Layout 인수를 받는 다른 CuTe 함수들과 달리, 이들은 logical_product 이후에 각 모드가 다시 결합될 수 있도록 인수의 최상위 랭크를 고려한다.
blocked product
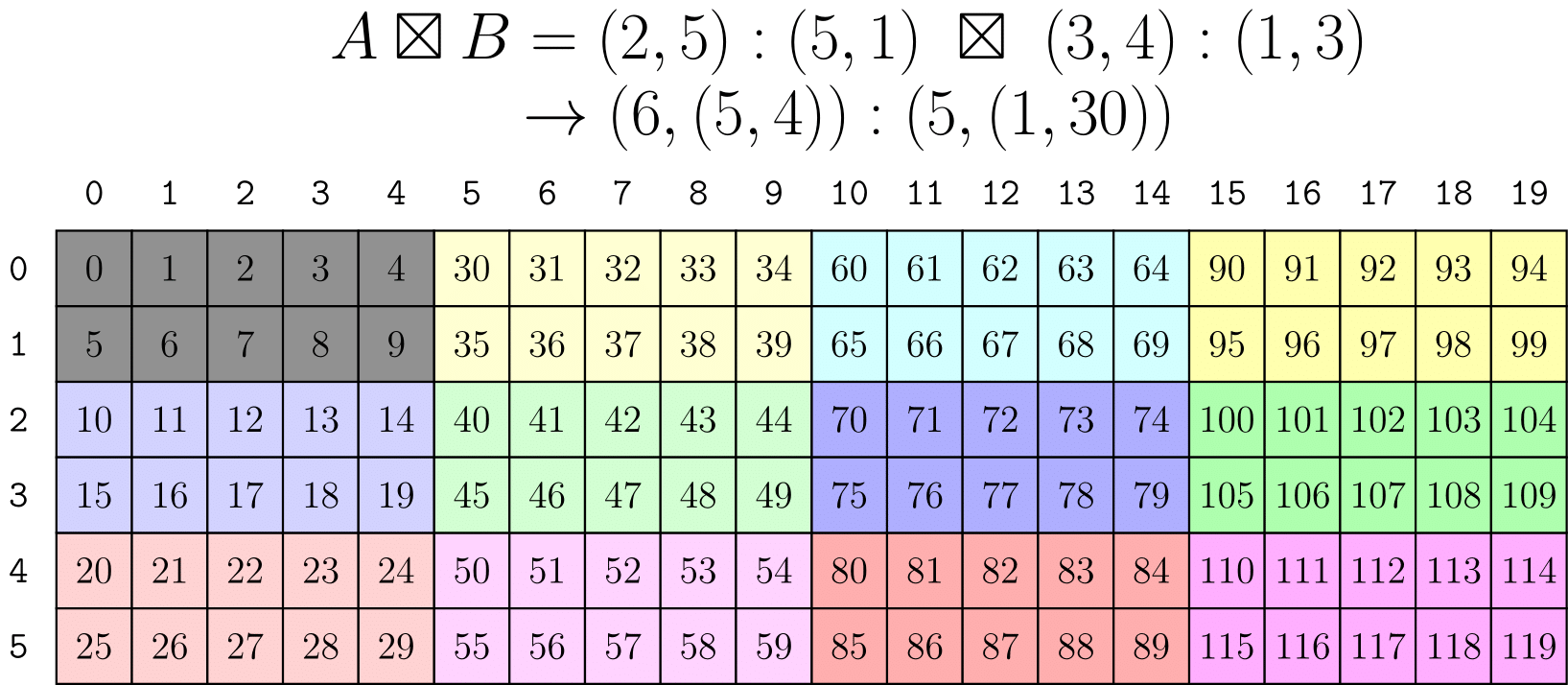
위 이미지는 tiler 방식과 동일한 결과를 보여주지만, 훨씬 더 직관적인 인수를 사용한다.
2x5 행 우선 레이아웃이 3x4 열 우선 배열 내의 타일로 배치되었다.
또한 blocked_product는 coalesced 모드-0을 처리했다는 점에 유의하십시오.
raked product

마찬가지로, raked_product는 모드들을 약간 다르게 결합한다.
결과물인 "열" 모드가 A "열" 모드 다음에 B "열" 모드가 오는 방식으로 구성되는 대신, 결과물인 "열" 모드는 B "열" 모드 다음에 A "열" 모드가 오는 방식으로 구성된다.
그 결과 "타일" A가 블록 형태로 나타나는 대신 "타일의 레이아웃(layout-of-tiles)" B와 교차 배치되거나 "레이크(raked)"된다.
다른 자료에서는 이를 "순환 분포(cyclic distribution)"라고 부르기도 한다.
Zipped and Tiled Products
zipped_divide 및 tiled_divide와 유사하게, zipped_product 및 tiled_product는 모드별 logical_product의 결과로 생성된 모드들을 단순히 재배열한다.
Layout Shape : (M, N, L, ...)
Tiler Shape : <TileM, TileN>
logical_product : ((M,TileM), (N,TileN), L, ...)
zipped_product : ((M,N), (TileM,TileN,L,...))
tiled_product : ((M,N), TileM, TileN, L, ...)
flat_product : (M, N, TileM, TileN, L, ...)