CuTe Layout
CuTe DSL을 공부하면서 주요한 개념인 CuTe Layout이 한국어 자료가 거의 없기도 하고 nvidia의 공식 문서도 cpp 기준으로 작성되어 있어서 번역+약간 정리를 하면서 내용을 정리해보려고 한다. CuTe Layout Algebra도 정리 중인데 내용이 보강될 예정이다.
CuTe에서 Layout은 "좌표 공간(coordinate space) → 인덱스 공간(index space)"으로 가는 매핑 함수이다. 즉, 다차원 배열 접근을 “형태(Shape)”와 “stride(Stride)”로 추상화해서, 메모리 배치(row-major/column-major 등)가 바뀌어도 알고리즘 코드를 거의 그대로 유지하게 만드는 게 핵심이다.
여기서 중요한 관점은,
- Layout을 "데이터를 어떻게 저장했는지" 설명하는 메타데이터로만 보지 말고,
- "좌표를 넣으면 어떤 선형 인덱스가 나오는지" 계산하는 함수로 보면 이후(algebra)가 훨씬 자연스럽게 이어진다.
Fundamental Types and Concepts
Integers
CuTe는 정적 정수와 동적 정수를 동일하게 처리하려고 시도한다. 모든 동적 정수는 정적 정수로 대체될 수 있으며 그 반대도 가능하다고 한다.
CuTe에서 "정수"라고 말할 때는 거의 항상 정적 정수 또는 동적 정수를 의미한다.
Python DSL에서는 보통, 정적 상수는 cutlass.Constexpr[int] 타입으로 받은 값, 동적 정수는 cutlass.Int32 같은 런타임 타입으로 받은 값이다.
Tuple & IntTuple
튜플은 0개 이상의 요소로 이루어진 유한하고 순서가 있는 리스트이다.
CuTe는 IntTuple 개념을 정수 또는 IntTuple의 튜플로 정의한다. 이 정의는 재귀적이여서 중첩 튜플이 가능하다. Python DSL에서는 그냥 정수 또는 정수로 이루어진 튜플로 표현한다.
정의된 연산
cute.rank(IntTuple):IntTuple의 요소 개수. 단일 정수는 랭크가 1이며, 튜플은 랭크가 tuple_size임.cute.depth(IntTuple): 계층적IntTuple의 개수이다. 단일 정수는 깊이가 0이고, 정수 튜플은 깊이가 1이며, 정수 튜플을 포함하는 튜플은 깊이가 2인 식이다.cute.size(IntTuple):IntTuple의 모든 요소의 곱cute.get(IntTuple, I):IntTuple의I번째 요소
t = ((1,2), (3,4))
cute.printf("t.rank={}, t.depth={}, t.size={}, t.get(0)={}, t.get(1)={}", cute.rank(t), cute.depth(t), cute.size(t), cute.get(t, (0,)), cute.get(t, (1,)))
위 코드의 출력은 다음과 같다.
t.rank=2, t.depth=2, t.size=24, t.get(0)=(1,2), t.get(1)=(3,4)
Layout, Shape, Stride & Tensor
Shape와 Stride는 모두 IntTuple로 구성된다.
Layout은 (Shape, Stride)의 튜플이다. 의미론적으로, 이는 Stride를 통해 Shape 내의 모든 좌표를 인덱스로 매핑하는 기능을 구현한다.
주로 표기는 Shape:Stride로 표기한다.
Layout은 포인터나 배열과 같은 데이터와 결합하여 Tensor를 생성할 수 있다. Layout에 의해 생성된 인덱스는 반복자(iterator)를 참조하여 적절한 데이터를 검색하는 데 사용된다.
Layout의 생성 및 사용
make_layout: Shape/Stride로 레이아웃 만들기
Python DSL의 cute.make_layout(shape, stride=...)는 C++의 make_layout(make_shape(...), make_stride(...))에 해당한다.
stride를 생략할 경우, LayoutLeft를 기본으로 하여 생성된다.
LayoutLeft는 Shape의 계층 구조와 상관없이 왼쪽에서 오른쪽으로 Shape의 배타적 접두사 곱(exclusive prefix product)으로 스트라이드를 생성한다. 이는 "일반화된 열 우선(column-major) 스트라이드 생성"으로 간주될 수 있습니다.
LayoutRight는 Shape의 계층 구조와 상관없이 오른쪽에서 왼쪽으로 Shape의 배타적 접두사 곱으로 스트라이드를 생성한다. 깊이가 1인 형상(shape)의 경우 이는 "행 우선(row-major) 스트라이드 생성"으로 간주될 수 있다.
계층적 형상의 경우 결과 스트라이드가 예상과 다를 수 있다. 예를 들어, 위 s2xh4 의 스트라이드는 LayoutRight 으로 생성될 수 있다.
Python DSL에서는 LayoutRight로 자동으로 생성하는 옵션은 없는 듯하다. 다만 make_ordered_layout를 활용하면 stride를 계산하지 않고도 layout을 생성할 수 있다. 만들려고 하는 layout이 LayoutRight인 경우, Shape와 동일한 형태의 order를 우측부터 좌측으로 0, 1, 2, ... 순서로 지정하면 된다.
Shape와 Stride는 합동(congruent)이어야 한다. 즉, Shape와 Stride는 동일한 튜플 크기를 가진다.
cute.is_congruent(shape, stride)로 확인할 수 있다.
s2xd4_a = cute.make_layout((2, cute.Int32(4)), stride=(12, 1))
s2xd4_col = cute.make_layout((2, cute.Int32(4)))
s2xd4_row = cute.make_layout((2, cute.Int32(4)), stride=(4, 1))
"""
static print s2xd4_col: {} (2,?):(1,2)
static print s2xd4_row: {} (2,?):(4,1)
dynamic print s2xd4_col: (2,4):(1,2)
dynamic print s2xd4_row: (2,4):(4,1)
"""
s2xh4 = cute.make_layout((2, (2, 2)), stride=(4, (2, 1)))
s2xh4_col = cute.make_layout(s2xh4.shape)
"""
dynamic print s2xh4: (2,(2,2)):(4,(2,1))
dynamic print s2xh4_col: (2,(2,2)):(1,(2,4))
"""
s2xh4_col = cute.make_ordered_layout((2, (2, 2)), (0, (1, 2)))
s2xh4_row = cute.make_ordered_layout((2, (2, 2)), (2, (1, 0)))
"""
dynamic print s2xh4_col: (2,(2,2)):(1,(2,4))
dynamic print s2xh4_row: (2,(2,2)):(4,(2,1))
"""
Hierarchical access functions
나중에 다룰 예정.
Layout Compatibility & Coordinates
Layout의 용도는 Shape에 의해 정의된 좌표 공간과 Stride에 의해 정의된 인덱스 공간 사이를 매핑하는 것이다.
layout(m,n) 구문은 논리적인 2D 좌표 (m,n)에서 1D 인덱스로의 매핑을 제공한다.
> print2D(s2xs4) # (2, 4):(1, 2)
0 2 4 6
1 3 5 7
> print2D(s2xd4_a) # (2, 4):(12, 1)
0 1 2 3
12 13 14 15
> print2D(s2xh4_col) # (2, (2, 2)):(1, (2, 4))
0 2 4 6
1 3 5 7
> print2D(s2xh4) # (2, (2, 2)):(4, (2, 1))
0 2 1 3
4 6 5 7
[print2D 참고](./13-layout.py)
흥미롭게도, s2xh4 예제는 행 우선(row-major)도 열 우선(column-major)도 아니다.
게다가 세 개의 모드를 가지고 있음에도 여전히 랭크-2로 해석되며 2D 좌표를 사용하고 있다.
구체적으로, s2xh4는 두 번째 모드에 2D 멀티 모드를 가지고 있지만, 우리는 여전히 해당 모드에 대해 1D 좌표를 사용할 수 있다.
> print1D(s2xs4) # (2, 4):(1, 2)
0 1 2 3 4 5 6 7
> print1D(s2xd4_a) # (2, 4):(12,1)
0 12 1 13 2 14 3 15
> print1D(s2xh4_col) # (2, (2, 2)):(1, (2, 4))
0 1 2 3 4 5 6 7
> print1D(s2xh4) # (2, (2, 2)):(4, (2, 1))
0 4 2 6 1 5 3 7
전체 레이아웃을 포함하여 레이아웃의 모든 멀티 모드(multi-mode)는 1차원 좌표를 허용한다.
개인적으로 경험한 Layout 좌표 생각하는 방법
Layout 좌표를 생각하는 방법은 다음과 같다.
- 우선 1-D인지 2-D인지 확인한다.
- 정해졌다면 해당 축에 있는 nested mode들은 그냥 flatten 시켜서 생각한다.
- 가장 왼쪽의 mode부터 shape 갯수를 맞춰서 stride를 더해주고 하나의 tuple(?) 처럼 생각한다.
- 갯수가 맞춰졌으면 다시 남은 것 중 가장 왼쪽의 mode를 골라 shpae 갯수를 맞춰서 tuple에 stride를 더하여 또 tuple로 만든다.
- 더이상 남은 mode가 없어질 때까지 반복한다.
- 해당 mode에 대해 평탄화한다.
예를 들어, (2, (2, 2)):(4, (2, 1))를 1-D 평탄화 한다고 가정해보자.
- 1-D이다.
- (2, 2, 2):(4, 2, 1)을 다룬다고 생각한다.
- 가장 왼쪽 shape 2와 stride 4를 맞춰주기 위해 (0, 4)를 만든다.
- 다음 왼쪽 shape 2와 stride 2를 맞춰주기 위해 ((0, 4), (2, 6))을 만든다.
- 다음 왼쪽 shape 2와 stride 1을 맞춰주기 위해 (((0, 4), (2, 6)), ((1, 5), (3, 7)))을 만든다.
- 평탄화 하여 0, 4, 2, 6, 1, 5, 3, 7을 얻는다.
비슷하게 2-D 좌표에 대해서도 각각축에 대해 적용하면 되는 것 같다.
벡터 레이아웃
rank == 1을 가진 모든 Layout을 벡터라고 정의한다.
(원문: We define a vector as any Layout with rank == 1)
레이아웃 8:1은 인덱스가 연속적인 8-요소 벡터로 해석될 수 있다. 마찬가지로, 레이아웃 8:2는 요소의 인덱스가 2의 스트라이드를 갖는 8-요소 벡터로 해석될 수 있다.
랭크-1의 정의에 따라 레이아웃 ((4,2)):((2,1))의 형상이 랭크-1이므로 이를 벡터로 해석할 수도 있다. 내부 형상은 4x2 행 우선(row-major) 행렬처럼 보이지만, 추가된 괄호 쌍 때문에 이 두 모드를 하나의 1차원 8-요소 벡터로 해석할 수 있다.
Layout: ((4,2)):((2,1))
Coord : 0 1 2 3 4 5 6 7
Index : 0 2 4 6 1 3 5 7
레이아웃 ((4,2)):((1,4))를 살펴보면, 이는 1 의 스트라이드를 갖는 4 개의 요소가 있고, 그 첫 번째 요소들이 4 의 스트라이드로 2 개 나열된 형태이다.
Layout: ((4,2)):((1,4))
Coord : 0 1 2 3 4 5 6 7
Index : 0 1 2 3 4 5 6 7
이것은 레이아웃 8:1과 동일하다(identical). 좌표와 인덱스가 같으므로 항등 함수(identity function)이다.
행렬 레이아웃
일반화하여, 우리는 랭크-2인 모든 Layout을 행렬로 정의한다.
벡터 레이아웃과 마찬가지로, 행렬의 각 모드(mode) 또한 멀티 모드로 분할될 수 있다. 이를 통해 단순한 행 우선이나 열 우선 이상의 다양한 레이아웃을 표현할 수 있다. 또한 여전히 2D 좌표를 사용하여 인덱싱할 수 있다.
Layout Compatibility (레이아웃 호환성)
레이아웃 A의 shape가 레이아웃 B의 shape와 호환된다면, 레이아웃 A는 레이아웃 B와 호환된다고 한다. shape A가 shape B와 호환되려면 다음 조건을 만족해야 한다.
- A와 B의 크기가 같아야 한다.
- A 내의 모든 좌표가 B 내에서도 유효한 좌표여야 한다.
호환성은 구조를 추가/세분화하는 방향만 허용하고, 구조를 제거/병합하는 것은 허용하지 않는다.
예제
- Shape 24는 Shape 32와 호환되지 않는다.
- Shape 24는 Shape (4,6)과 호환된다.
- Shape (4,6)은 Shape ((2,2),6)과 호환된다.
- Shape ((2,2),6)은 Shape ((2,2),(3,2))와 호환된다.
- Shape ((2,2),(3,2))는 Shape ((2,3),4)와 호환되지 않는다.
- Shape 24는 Shape ((2,2),(3,2))와 호환된다.
- Shape 24는 Shape ((2,3),4)와 호환된다.
- Shape ((2,3),4)는 Shape ((2,2),(3,2))와 호환되지 않는다.
- Shape 24는 Shape (24)와 호환된다.
- Shape (24)는 Shape 24와 호환되지 않는다.
- Shape (24)는 Shape (4,6)과 호환되지 않는다.
즉, 호환성(compatible)은 반사성(reflexive), 반대칭성(antisymmetric), 추이성(transitive)을 가지므로 Shape에 대한 약한 부분 순서(weak partial order)이다.
- 반사성: A는 자기 자신과 호환, 예) 24 ↔ 24
- 반대칭성: A→B, B→A 둘 다 성립하면 A=B, 예) (24)→24 안됨, 24→(24) 됨
- 추이성: A→B, B→C면 A→C, 예) 24→(4,6), (4,6)→((2,2),6) ⇒ 24→((2,2),6)
Layout Coordinates (레이아웃 좌표)
위의 호환성 개념에 따라, 모든 Layout은 여러 종류의 좌표를 수용할 수 있다.
모든 Layout은 자신과 호환되는 모든 Shape에 대한 좌표를 수용한다.
CuTe는 역사전식 순서(colexicographical order, 왼쪽에서 오른쪽으로 읽는 "사전식"과 달리 오른쪽에서 왼쪽으로 읽음)를 통해 이러한 좌표 집합 간의 매핑을 제공한다.
따라서 모든 Layout은 두 가지 fundamental mapping을 제공한다.
Shape를 통해 입력 좌표를 그에 대응하는 자연 좌표(natural coordinate)로 매핑하는 것: 논리적으로 어떤 순서로 방문할지("몇 번째 요소?")Stride를 통해 자연 좌표를 그에 대응하는 인덱스(index)로 매핑하는 것: 물리적으로 메모리 어디에 있는지("메모리 주소는?")
즉, 입력 좌표의 순회 방식과 실제 메모리 접근 패턴은 별개이다.
좌표 매핑 (Coordinate Mapping)
입력 좌표에서 자연 좌표로의 매핑은 Shape 내에서 역사전식 순서를 적용한 것이다.
여기서 역사전식 순서는 column-major order와 유사하다. 사전식 순서는 row-major order라고 생각하면 된다.
예를 들어 Shape (3,(2,3)) 를 살펴보면, 이 Shape는 세 가지 좌표 집합을 가진다. 1차원 좌표, 2차원 좌표, 그리고 자연(h-D) 좌표
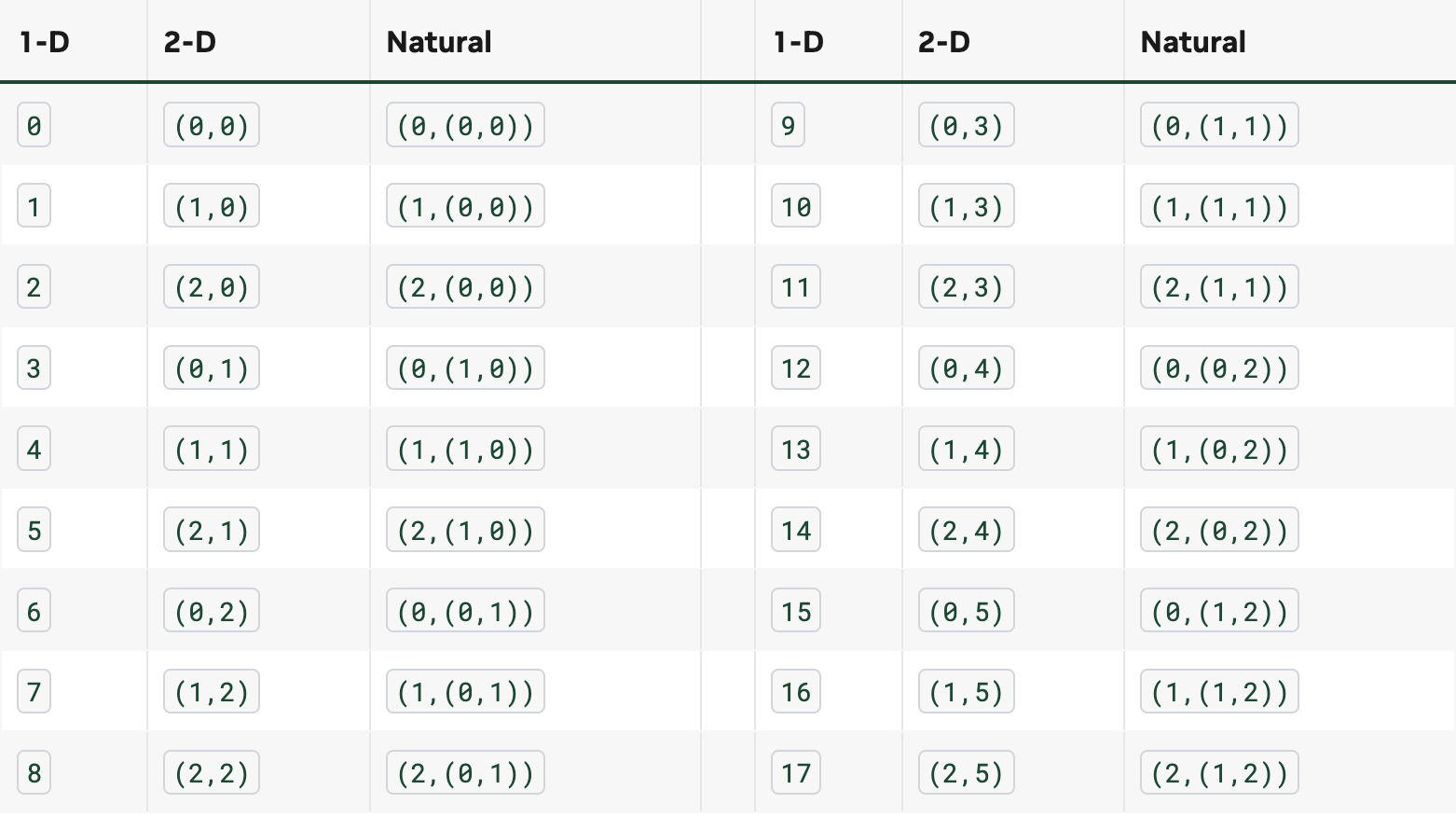
형태 (3,(2,3))에 대한 각 좌표는 두 개의 동등한 좌표를 가지며, 모든 동등한 좌표는 동일한 자연 좌표로 매핑된다. 위의 모든 좌표가 유효한 입력이므로, 형태 (3,(2,3))을 가진 레이아웃은 1차원 좌표를 사용하여 18개 요소의 1차원 배열처럼, 2차원 좌표를 사용하여 3x6 요소의 2차원 행렬처럼, 또는 h차원(자연) 좌표를 사용하여 3x(2x3) 요소의 h차원 텐서처럼 사용할 수 있다. 이 세 좌표가 "서로 같은 원소 집합을 다른 방식으로 인덱싱한 것"임을 보여준다. 수학적으로, 두 집합 사이에 양방향 1:1 대응(전단사, bijective)이 있고 구조가 보존되면 이를 동형사상(isomorphism)이라고 한다. 여기서는 1차원 정수 집합 [0, 18)과 다차원 좌표 공간 [0,3) × [0,2) × [0,3) 사이에 동형사상이 존재하므로, 어느 방식으로 접근하든 같은 원소를 가리킨다.
이전의 1차원 출력은 CuTe가 2차원 좌표의 역사전식 순서를 통해 1차원 좌표를 식별하는 방법을 보여준다. i = 0 에서 size(layout)까지 반복하며 단일 정수 좌표 i 로 레이아웃을 인덱싱하면, 레이아웃이 좌표를 행 우선(row-major) 방식이나 더 복잡한 방식으로 인덱스에 매핑하더라도 이 "일반화된 열 우선(generalized-column-major)" 순서로 2차원 좌표를 탐색하게 된다.
함수 cute.idx2crd(idx, shape)는 좌표 매핑을 담당한다. 이 함수는 형태 내의 임의의 좌표를 가져와 해당 형태에 대한 동등한 자연 좌표를 계산합니다.
레이아웃의 Stride가 어떻든 상관없이, 1차원 정수 i로 순회하면 CuTe는 항상 역사전식(column-major)으로 좌표를 탐색한다.
이러한 분리 덕분에 알고리즘 코드는 그대로 두고, Stride만 바꾸면 다른 메모리 레이아웃에 적용할 수 있다.
인덱스 매핑 (Index Mapping)
자연 좌표에서 인덱스로의 매핑은 자연 좌표와 Layout의 Stride를 내적하여 수행된다.
레이아웃 (3,(2,3)):(3,(12,1))을 예로 들어보면 내적 좌표 (i,(j,k))는 인덱스 i*3 + j*12 + k*1이 된다.
이 레이아웃이 계산하는 인덱스는 아래의 2차원 표에 표시되어 있으며, 여기서 i는 행 좌표로, (j,k)는 열 좌표로 사용된다.
0 1 2 3 4 5 <== 1-D col coord
(0,0) (1,0) (0,1) (1,1) (0,2) (1,2) <== 2-D col coord (j,k)
+-----+-----+-----+-----+-----+-----+
0 | 0 | 12 | 1 | 13 | 2 | 14 |
+-----+-----+-----+-----+-----+-----+
1 | 3 | 15 | 4 | 16 | 5 | 17 |
+-----+-----+-----+-----+-----+-----+
2 | 6 | 18 | 7 | 19 | 8 | 20 |
+-----+-----+-----+-----+-----+-----+
함수 cute.crd2idx(c, layout)은 인덱스 매핑을 담당한다.
이 함수는 shape 내의 임의의 좌표를 받아 해당 shape에 상응하는 자연 좌표를 계산하고(아직 계산되지 않은 경우), stride와의 내적을 계산한다.
Layout Manipulation (레이아웃 조작)
- 서브레이아웃 (sublayouts)
cute.get(layout, mode=[I...])cute.select(layout, mode=[I...])
- 연접 (concatenation)
cute.append(layout1, layout2): layout2를 layout1 뒤에 붙임cute.prepend(layout1, layout2): layout2를 layout1 앞에 붙임
a = cute.make_layout(3, stride=1) # a: 3:1
b = cute.make_layout(4, stride=3) # b: 4:3
ab = cute.append(a, b) # ab: (3,4):(1,3)
ba = cute.prepend(a, b) # ba: (4,3):(3,1)
c = cute.append(ab, ab) # c: (3,4,(3,4)):(1,3,(1,3))
- 그룹화 및 평탄화 (grouping and flattening)
cute.group_modes(layout, begin, end): begin부터 end(미포함)까지의 모드들을 그룹화하여 새로운 레이아웃을 생성cute.flatten(layout): 레이아웃을 평탄화하여 1차원으로 만듬- 모드를 그룹화, 평탄화 및 재정렬함으로써 텐서를 행렬로, 행렬을 벡터로, 벡터를 행렬로 변환하는 등 텐서를 제자리에서 재해석할 수 있다.
a = cute.make_ordered_layout((2, 3, 5, 7), (0, 1, 2, 3)) # a: (2,3,5,7):(1,2,6,30)
b = cute.group_modes(a, 0, 2) # b: ((2,3),5,7):((1,2),6,30)
c = cute.group_modes(b, 1, 3) # c: ((2,3),(5,7)):((1,2),(6,30))
f = cute.flatten(b) # f: (2,3,5,7):(1,2,6,30)
e = cute.flatten(c) # e: (2,3,5,7):(1,2,6,30)
- 슬라이싱 (slicing)
Layout도 slicing 연산이 가능하지만Tensor에서 수행하는 것을 권장한다.
참고문헌
원글