GPU MODE Lecture 23 Tensor Cores 정리
생각과는 다르게 사실상 CUTLASS 소개에 가까운 영상이였다.
Source: Lecture 23: Tensor Cores
evolution over the years
- pascal: 스레드당 하나 이상의 요소로 저정밀도 점곱을 수행(텐서 코어 이전)
- volta: 8개의 스레드가 참여하여 8x8x4 곱셈을 진행함.
- ampere: 워프레벨 tensor core를 사용하여 16x8x8 곱셈을 진행함.
- hopper: 4개의 워프가 협력하여 공유 메모리에서 직접 거대한 행렬 곱셈을 수행함.(64x16x16)
행렬 곱이 어려운 이유?
- 전체 행렬을 스레드 블록 수준으로 타일링하고 다시 스레드 수준으로 타일링 해야함.
- 정말 어려워지는 부분은 이 모든 인덱스를 추적하는 것.
- 그리고 데이터와 주소 연산이 실제 행렬 곱셈 비용을 잠식하지 않도록 하는것.
- 텐서코어를 도입하면 특정한 스레드 레이아웃을 가지고 있어서 올바른 실행을 위해 입력 피연산자가 특정 순서로 정렬되어야함. (더 어려워짐.)
파티셔닝 문제
- 텐서 코어 프로그램 작성의 첫번째 과제
- 어떤 스레드가 어떤 데이터 요소를 소유하는지 파악하는 것
비동기성 관리
- 프로그래머는 텐서 코어로 데이터를 스트리밍하는 소프트웨어 파이프라인을 설정해야 함.
- 메모리 로드의 지연시간이 텐서코어로 계산할 경우 계산 속도를 늦추지 않을 것이라는점
- 깊은 비동기 파이프라인을 통해 지연시간을 허용하고 고정 비용을 최적화하는 것을 관리함
- 텐서코어 연산이 점점 빨라지고 있기 때문에 지연시간에 대해 정말로 걱정하기 시작해야함.
CUTLASS
- 타일레벨 프로그래밍 모델 제공.
- nvidia GPU를 위한 공개 텐서 프로그래밍 모델
- 커스텀 커널 작성을 위한 개발자 생산성에 집중
- 가능한한 많은 조합성을 제공하는 것을 목표로 함.
- 모든 조합이 가능하지는 않는다는 점에서 정적 어설션을 제공하여 컴파일 되지 않게함.
- 단일화되고 명확한 커스터마이징을 제공, 러닝커브를 낮춤.
feature
- convolution
- GEMM (mixed-input, grouped)
- Epilogue Fusions
- fp8 gemms
- tile schedulers for composable load balancing
pip install nvidia-cutlass
CuTe Layouts and Layout Algebra
- CuTe는 cutlass3의 핵심 필수 구성 요소, cutlass3는 cute의 super set
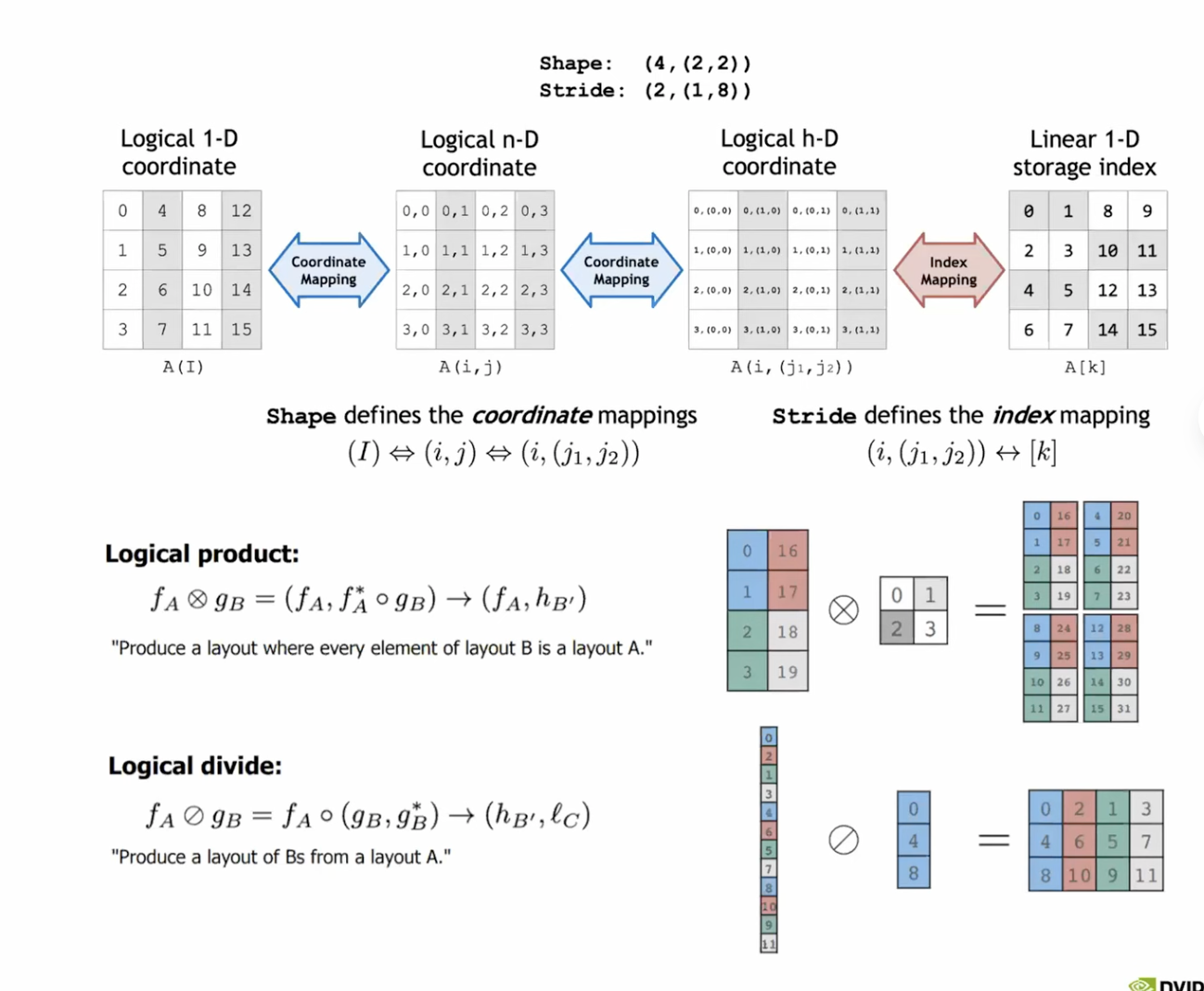
- CuTe는 canonical layout representation을 제공함.
- 각 레이아웃은 shape와 stride의 조합으로 처리됨.
- 레이아웃은 근본적으로 계층적(hierarchical)이며 multi-modal임.
- multi-modal 예시: Shape가 (4, (2, 2))이면 기본적으로 2차원인데 두번째 차원의 모양이 또 2차원임.
- 좌표의 논리적 일관성을 유지함.
- 우리가 좌표를 인덱스로 매핑하는 일을 걱정하지 않게 해줌.
- 스위즐(swizzle) 펑터를 사용하여 스위즐 함수 개발을 매우 쉽게 만들 수 있음.
- CuTe는 형식화된 레이아웃 대수를 제공함(Formalized algebra of layouts)
- 여러 레이아웃을 함께 compose 하면 반환유형은 또다른 레이아웃임.
- 스레드 레이아웃과 데이터 레이아웃이 분리되고 layout algebra로 구분함
- 스레드 레이아웃: 스레드들이 논리적으로 어떻게 배열되는지 (예: 32×4 그리드)
- 데이터 레이아웃: 텐서가 메모리에 어떻게 저장되는지 (row-major, column-major 등)
- 선형 대수 구성 요소의 개념적 계층 구조를 공식화 함.
- 기본적으로 움직이는 부분을 직교축으로 분해하는 방식으로
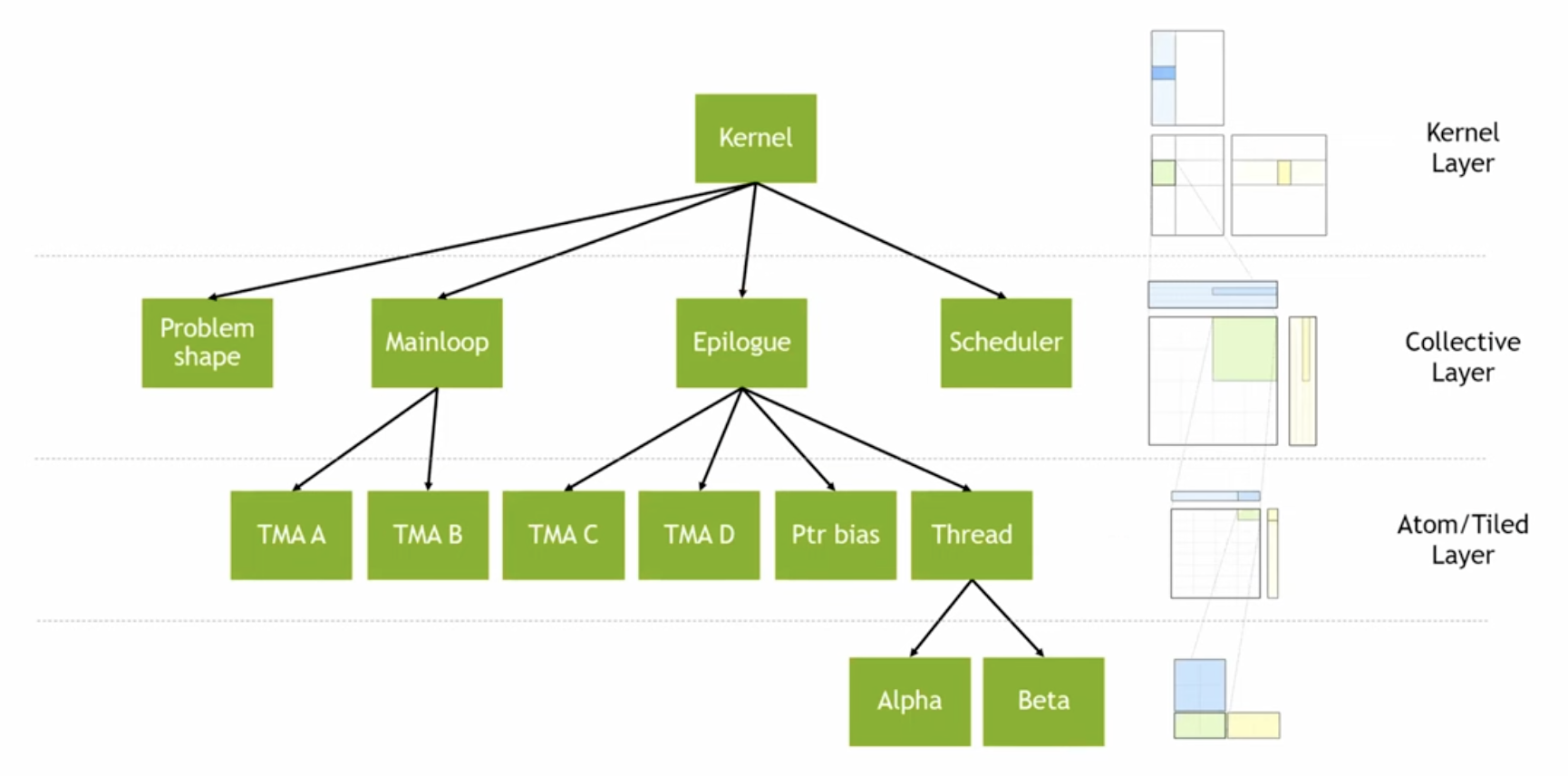
CUTLASS 3 Conceptual Hierarchy
- Atom layer
- 하드웨어적으로 지원되는 아키텍쳐 명령과 cute layout으로 전사되는 관련 메타 정보에 해당함.
- 아키텍처가 가속하는 특정 수학/복사 연산에 반드시 참여해야 하는 스레드와 값의 최소 집합
- Tiled MMA/Copy: Spatial Microkernel layer
- 수학 및 복사 연산의 완전한 공간 타일링을 추상화함.
- 여기서 공간은 (우리가 표현하고 싶은) 스레드와 데이터, 그리고 이들의 모든 순열을 의미.
- 이 레이어는 명령 어 레이아웃이 아무리 복잡해지더라도 아키텍쳐별 작업에 대한 표준 루프를 작성할 수 있게 해줌.
- 복사를 위해 단일 for 루프를 사용할 수 있다는 것을 의미함.
- 그리고 GEMM을 위해 삼중 중첩 for 루프를 사용할 수 있다는 것을 의미함.
- 레이아웃과 인덱스 장부 정리 문제를 해결해줌.
- 수학 및 복사 연산의 완전한 공간 타일링을 추상화함.
- Collective layer: Temporal Microkernel layer
- 하나의 출력 타일을 계산하는 여러 공간적 마이크로 커널의 완전한 시간적 타일링을 추상화함.
- 아키텍쳐별 동기화, warp specialization, pipelining, 명령어 인터리빙을 사용하는 multiple tiling 오케스트레이션으로 볼 수 있음.
- 공유 메모리 관리까지 추상화하고 추론할 수 있게 해줌.
- Kernel layer: collective를 호출하는 외부 루프
- 다양한 출력타일에 걸쳐 여러 작업을 수행함.
- 로드 밸런싱
- 스레드를 전문화 된 영역으로 마샬링(marshalling)
- 얼마나 많은 스레드 블록을 실행할지, 얼마나 많은 클러스터를 설정할지 결정하는 그리드 플래닝(grid planning)
- 호스트 측에서 오는 인수를 구성하고 실제로 커널이 수행될때 ABI에 매핑함.
- 다양한 출력타일에 걸쳐 여러 작업을 수행함.
- Device layer: host side setup and interface
- CUTLASS의 장치 계층은 덧대기일 뿐
CUTLASS 3 API
- Spatial microkernels: cute::Tile{Mma|Copy}<>
- Temporal Microkernels: collective::Collective{Mma|Conv|Epilogue|Transform}<>
- 단일 출력 타일을 계산함.
- warp-specialization을 사용하여 warp 내에서 최적화해야할 수 있음.
- Kernel layer: kernel::{Gemm|Conv}Universal<>
- 커널 계층은 근본적으로 mainloop collective와 epilogue collective의 구성이라는 것
- 중요한것은 스케줄러: 전체 전역 메모리 문제가 이러한 collective들 사이에서 어떻게 분해되는지 조율하는 것
- Device layer: device::{Gemm|Conv}UniversalAdapter<>
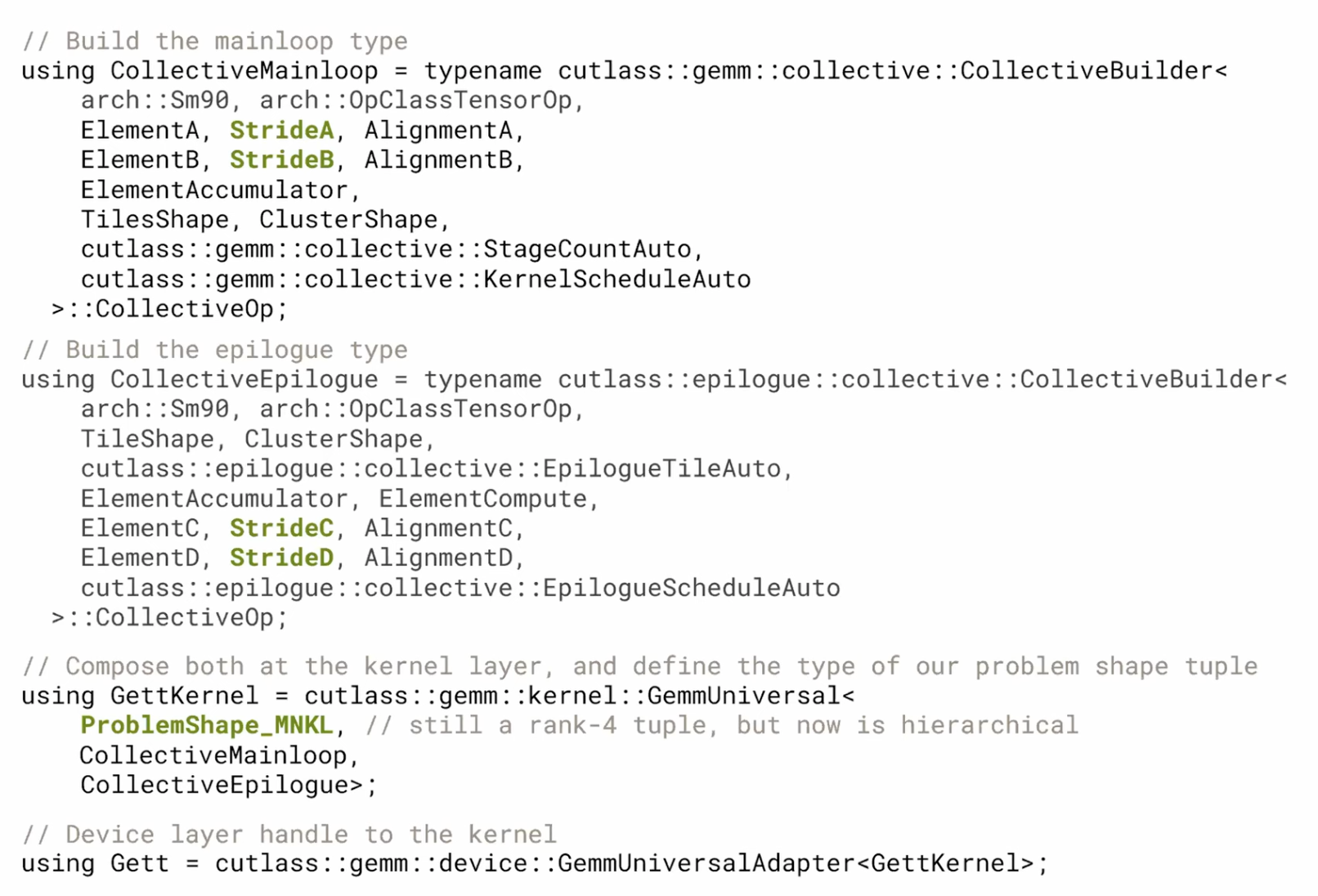
Writing Custom Kernels
- 커스텀 메인루프(마이크로커널)를 작성하고, 디스패치 정책을 통해 기존 스케줄(외부 루프)과 조합할 수 있음
- 커스텀 스케줄(외부 루프)을 작성하고, 디스패치 정책을 통해 기존 메인루프(마이크로커널)와 조합할 수 있음
- 커널 레이어는 입출력 텐서의 개수나 연산의 의미에 완전히 무관함
- 커널은 메인루프 + 에필로그 + 타일 스케줄러의 조합이며, 이들을 자유롭게 구성할 수 있음
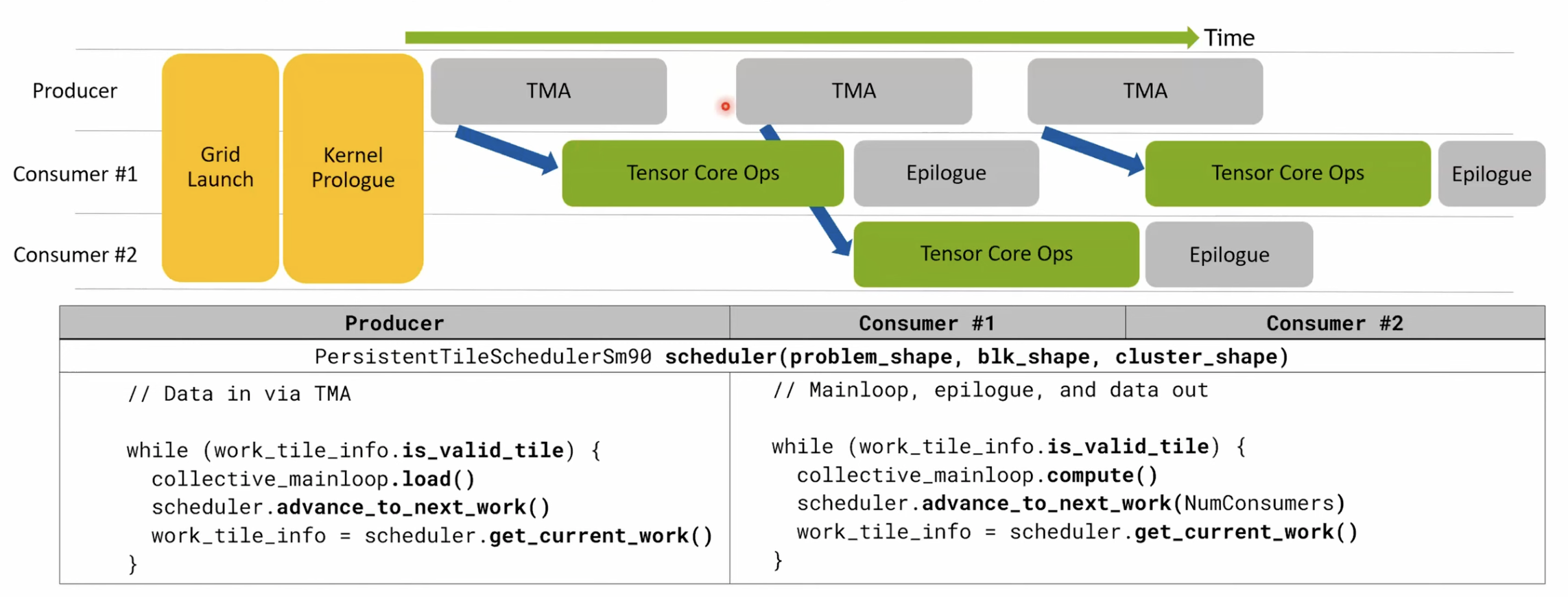
cutlass 3.0의 동시성과 동기화 이점
- GPU 프로그래밍은 레이아웃을 올바르게 설정하는 것보다 동시성과 동기화를 올바르게 설정하는 것에 더 가까움.
- 최고 성능으로 실행되는 호퍼 커널을 작성하려면 코등에 효과적으로 동기화 그래프를 작성해야함.
- 파이프라인을 재사용하고 구현한다면 스레드의 스케줄링과 동기화를 계층적으로 분해함.
- 노드를 동기화 노드의 서브 그래프로 작성할 수 있음.
- 동기화 디버깅이 쉬워짐.
- 데이터를 로컬 및 레이아웃과 같이 계층적인 방식으로 나누는 것처럼 동기화도 나눌 수 있음.
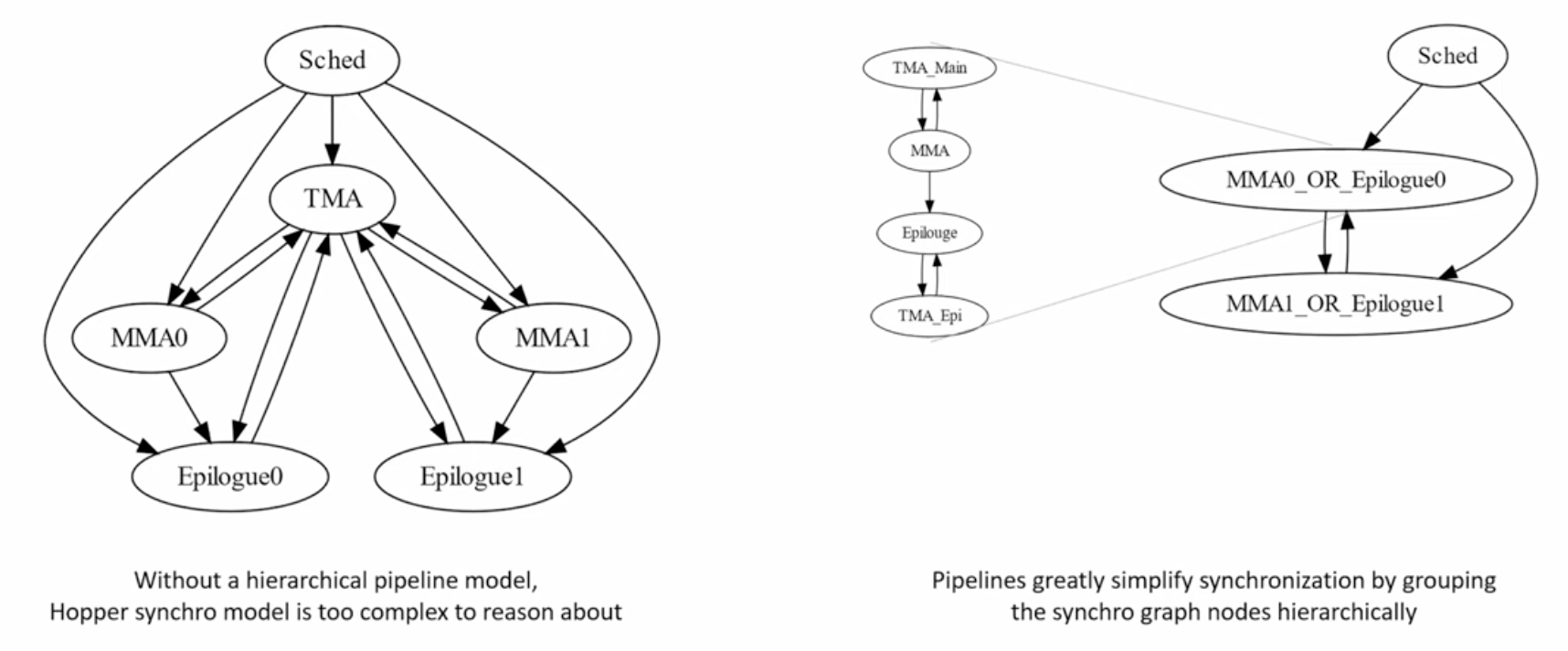
텐서 코어를 대상으로 하는 사용자 지정커널을 작성하기 위한 규칙
- 핵심은 변경사항을 영향을 받는 가장 작은 하위 집합으로 국한시키는 것.
- 커널 퓨전
- 기존 collective와 함께 구성되는 사용자 지정 커널 스케줄을 작성함.
- 텐서코어 GEMM을 튜닝하면 많은 최적화를 무료로 얻을 수 있음.
- 최고 처리량으로 처리하는 건 매우 어려움.
- 이 경우 외부 루프 스케줄을 작성하면 훨씬더 성능 튜닝이 더 쉽고 기존 집합체와 구성할 수 있음
- 메인루프 퓨전
- 커널 스케줄을 동일하게 유지하고 기존 collective를 확장하고 사용자 정의할 수 있음.
- 새로운 디스패치 정책을 정의하기만 하면됨.
- 기존 커널 레이어와 결합하는 경우 모든 최적화를 무료로 얻을 수 있음
- 스트림 k, 지역성을 위한 모든 종류의 T 스위즐링처럼
- 에필로그 퓨전
- 같은 원리가 적용됨. 삶을 훨씬더 편하게 해줄 것.
- 실제로 코드를 수정할 필요가 전혀 없음.
- 커스텀 로드 밸런싱, L2 locality, outer loop shenanigans를 시도하는 경우
- 커스텀 타일 스케줄러만 작성하면 그시점부터는 다른 모든 것이 동일하게 유지됨.
Hopper GEMM Kernel Optimization 101
- TMA를 통한 Global Memory 접근
- 하드웨어 지원 경계 초과(Out-Of-Bounds) 판정, 일명 predication
- 레지스터 압박 및 ALU 연산 감소
- TMA와 연계하여 프로그래밍 가능한 멀티캐스트를 지원하는 Thread Block Cluster
- 시간적/공간적 지역성 활용을 통한 L2 대역폭 증폭. 단, 양자화(quantization)와 점유율(occupancy) 희생
- Shared Memory를 통한 깊은 소프트웨어 파이프라이닝
- 더 나은 지연 시간 커버리지. 단, 동시 실행 Thread Block 수 감소
- Warp-Group MMA 연산
- 여러 비동기 MMA 명령어가 동시 비행(in-flight) 중
- 비동기 TMA 생산자와 MMA 소비자 간의 Mbarrier 기반 동기화
- 뱅크 충돌 회피를 위한 Shared Memory 데이터 스위즐링
- MMA와 TMA가 함께 타일 크기와 데이터 타입을 규정
Hopper GEMM Kernel Optimization 201
- Warp Specialization (워프 특화)
- 다양한 시나리오에서 최적의 메모리 및 연산 처리량 달성
- Persistent Schedule (지속형 스케줄)
- 커널 내에서 하드웨어 및 소프트웨어 파이프라이닝의 고정 비용을 분산(amortize)
- MMA의 그림자 속에서 에필로그 숨기기 (일명 Ping-Pong Schedule)
- 작지만 연산 병목(compute bound)인 GEMM에 매우 중요
- 효율성 향상을 위한 타일 크기 최대화 (일명 Cooperative Schedule)
- 레지스터 압박의 더 나은 처리
- 동기화 프리미티브의 효율적 사용
Hopper GEMM Kernel Optimization 501
- 최적의 Thread Block 래스터화 및 스위즐링
- 지역성(locality) 활용 촉진
- https://github.com/NVIDIA/cutlass/blob/main/media/docs/efficient_gemm.md#threadblock-rasterization
- Stream-K 스케줄링
- 점유율(occupancy)과 효율성 간의 최적 트레이드오프 탐색
- https://arxiv.org/abs/2301.03598
- MMA 이전의 효율적인 입력 변환
- 레지스터 사용 최적화
- 파이프라인화된 RS 커널
- https://github.com/NVIDIA/cutlass/blob/main/include/cutlass/gemm/collective/sm90_mma_tma_gmma_rs_warpspecialized.hpp
- 최적의 명령어 시퀀스 생성
- 프리페칭, 캐시 관리
어떤 레시피를 언제 사용할까?
- Persistent 커널은 훌륭함! 거의 항상 이득
- "작은" K, 큰 MN 형태 → Persistent Ping-Pong 스케줄로 프롤로그/에필로그 오버헤드 숨기기
- 큰 K에서도 무거운 에필로그 퓨전이 있다면? → Ping-Pong Persistent
- "큰" K, 큰 MN 형태 → Cooperative Persistent
- 더 큰 누산기(acc) 타일을 위해 Multistage Persistent
- 단순 직접 저장(direct store) 에필로그로 메인루프에 더 많은 SMEM 용량 확보도 이득일 수 있음
- 작은 MN, 큰 K 형태 → Cooperative + Stream-K 로드 밸런싱
- HBM 대역폭 병목인 MN 형태? → L2 지역성을 위한 더 영리한 타일 래스터화
- FP8 학습의 경우 → 고정밀 누적을 수행하는 CUTLASS FP8 레시피 따르기
- FP8 양자화/역양자화의 경우 → amax 및 보조(aux) 텐서를 퓨징하는 CUTLASS 에필로그 참고
기타 경험 법칙
- 1 CTA / SM 점유율로 시작 – 더 높은 점유율은 최후의 수단으로만
- 클러스터 크기 2는 거의 항상 이득. 여기서 시작하여 가장 큰 타일 차원에 TMA 멀티캐스트 적용.
- 더 큰 타일 크기의 경우, M을 타일링하는 것보다 더 큰 WGMMA N 형태 선호
- 가능하면 WGMMA와 TMA에 더 큰 스위즐 사용 (타일 형태의 함수)
- 가능하면 A와 B 모두 SMEM에서 소싱
- K-major가 아닌 16비트 미만 입력 피연산자의 경우, 다음 순서로 선호
- swap AB 있든 없든 A를 RMEM에서 소싱하는 WGMMA 변형 사용
- swap AB + B에 대한 파이프라인화된 퓨즈드 전치(transpose)와 함께 A를 RMEM에서 소싱하는 WGMMA 변형 사용
- 에필로그 퓨전의 경우 – 여유가 많음
- 메인루프 퓨전의 경우
- 가능하면 이전 커널의 에필로그에 퓨즈
- A를 RMEM에서 소싱하는 WGMMA 변형 사용
- WGMMA B 입력에 퓨징 피하기 – SMEM 왕복이 발생하므로