LeetGPU GEMM T4 도전기 (baseline ~ wmma + tiling)
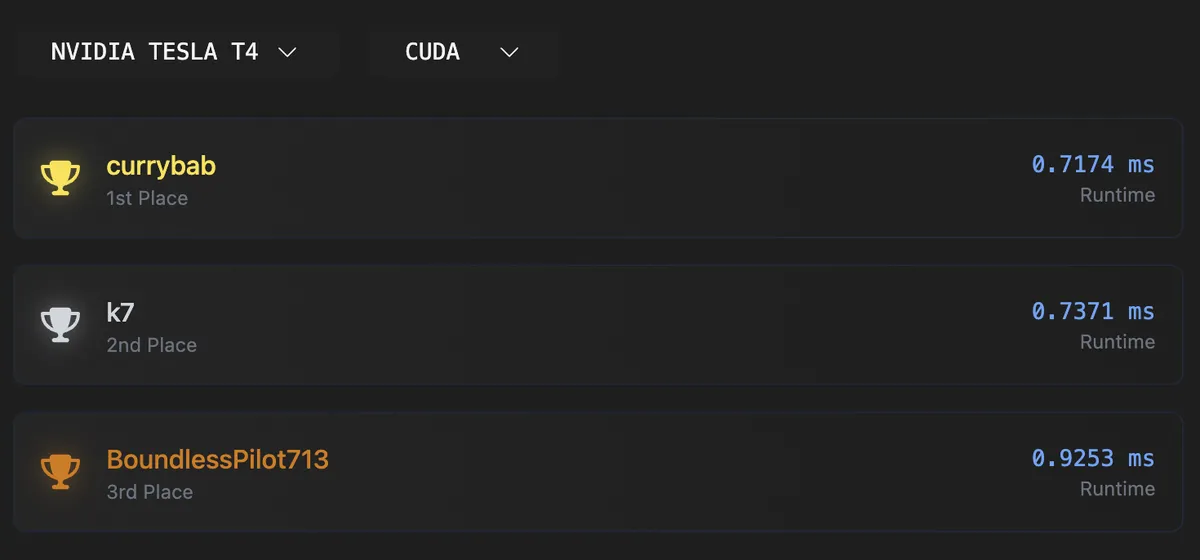
leetGPU에서 GEMM 문제를 풀어보았다. 앞으로 각 GPU 아키텍쳐에서 top3 성적을 목표로 기록해보고자 한다. 우선 T4 GPU에서 여러 최적화 여지를 남겨두었지만 1등을 달성하였다(기존 0.7371ms -> 0.7174ms로 2.67%정도 개선하였다.
Baseline 코드
우선 가장 기본으로 볼 수 있는 GEMM 구현체
#include <cuda_runtime.h>
#include <cuda_fp16.h>
__global__ void matmul(const half* A, const half* B, half* C, int M, int N, int K, float alpha, float beta) {
int gidx = threadIdx.x + blockDim.x * blockIdx.x;
int gidy = threadIdx.y + blockDim.y * blockIdx.y;
if (gidx >= N || gidy >= M) return;
float acc = 0.0f;
for (int i = 0; i < K; i++) {
float rA = __half2float(A[gidy * K + i]);
float rB = __half2float(B[i * N + gidx]);
acc = fma(rA, rB, acc);
}
C[gidy * N + gidx] = __float2half(acc * alpha + __half2float(C[gidy * N + gidx]) * beta);
}
// A, B, and C are device pointers
extern "C" void solve(const half* A, const half* B, half* C, int M, int N, int K, float alpha, float beta) {
dim3 threadsPerBlock(1, 1);
dim3 blocksPerGrid(N, M);
matmul<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, M, N, K, alpha, beta);
}
약 94.83ms를 소요하며, SOTA인 0.7371ms에 비해 128배 정도 느리다.
이를 개선하기 위해 우선 타일링을 사용해 본다.
Tiling 적용
#include <cuda_runtime.h>
#include <cuda_fp16.h>
#define TILE_SIZE 32
__global__ void matmul(const half* A, const half* B, half* C, int M, int N, int K, float alpha, float beta) {
int gidx = threadIdx.x + blockDim.x * blockIdx.x;
int gidy = threadIdx.y + blockDim.y * blockIdx.y;
__shared__ float sA[TILE_SIZE][TILE_SIZE];
__shared__ float sB[TILE_SIZE][TILE_SIZE];
float acc = 0.0f;
for (int tile_idx = 0; tile_idx < K; tile_idx += TILE_SIZE) {
// 타일 복사
int tile_x = threadIdx.x + tile_idx;
int tile_y = threadIdx.y + tile_idx;
if (tile_x < K && gidy < M) {
sA[threadIdx.y][threadIdx.x] = __half2float(A[gidy * K + tile_x]);
} else {
sA[threadIdx.y][threadIdx.x] = 0.0f;
}
if (tile_y < K && gidx < N) {
sB[threadIdx.y][threadIdx.x] = __half2float(B[N * tile_y + gidx]);
} else {
sB[threadIdx.y][threadIdx.x] = 0.0f;
}
__syncthreads();
// 연산
for (int i = 0; i < TILE_SIZE; i++) {
acc = fma(sA[threadIdx.y][i], sB[i][threadIdx.x], acc);
}
__syncthreads();
}
// 값 복사
if (gidx < N && gidy < M) {
C[gidy * N + gidx] = __float2half(acc * alpha + __half2float(C[gidy * N + gidx]) * beta);
}
}
// A, B, and C are device pointers
extern "C" void solve(const half* A, const half* B, half* C, int M, int N, int K, float alpha, float beta) {
dim3 threadsPerBlock(TILE_SIZE, TILE_SIZE);
dim3 blocksPerGrid((N + TILE_SIZE - 1) / TILE_SIZE, (M + TILE_SIZE - 1) / TILE_SIZE);
matmul<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, M, N, K, alpha, beta);
}
약 4.35ms를 소요하며 SOTA보다는 6배 느리지만, 그래도 20배 정도 개선 되었다. thread coarsening을 적용해보려고 한다.
Thread Coarsening 적용
#include <cuda_runtime.h>
#include <cuda_fp16.h>
#define TILE_SIZE 32
#define COARSE_M 4
#define COARSE_N 4
#define BLOCK_M (TILE_SIZE * COARSE_M)
#define BLOCK_N (TILE_SIZE * COARSE_N)
__global__ void matmul(const half* A, const half* B, half* C, int M, int N, int K, float alpha, float beta) {
int col = blockDim.x * blockIdx.x * COARSE_N;
int row = blockDim.y * blockIdx.y * COARSE_M;
int tidx = threadIdx.x;
int tidy = threadIdx.y;
__shared__ float sA[BLOCK_M][TILE_SIZE];
__shared__ float sB[TILE_SIZE][BLOCK_N];
float acc[COARSE_M][COARSE_N] = { 0.0f };
for (int k = 0; k < K; k += TILE_SIZE) {
// 타일 복사
int kx = tidx + k;
int ky = tidy + k;
#pragma unroll
for (int cm = 0; cm < COARSE_M; cm += 1) {
int ty = TILE_SIZE * cm + tidy;
if (kx < K && ty + row < M) {
sA[ty][tidx] = __half2float(A[(ty + row) * K + kx]);
} else {
sA[ty][tidx] = 0.0f;
}
}
#pragma unroll
for (int cn = 0; cn < COARSE_N; cn += 1) {
int tx = TILE_SIZE * cn + tidx;
if (ky < K && tx + col < N) {
sB[tidy][tx] = __half2float(B[N * ky + tx + col]);
} else {
sB[tidy][tx] = 0.0f;
}
}
__syncthreads();
// 연산
#pragma unroll
for (int i = 0; i < TILE_SIZE; i++) {
// shared -> register 복사
float rA[COARSE_M];
float rB[COARSE_N];
#pragma unroll
for (int cm = 0; cm < COARSE_M; cm++) {
rA[cm] = sA[tidy + TILE_SIZE * cm][i];
}
#pragma unroll
for (int cn = 0; cn < COARSE_N; cn++) {
rB[cn] = sB[i][tidx + TILE_SIZE * cn];
}
#pragma unroll
for (int cm = 0; cm < COARSE_M; cm++) {
#pragma unroll
for (int cn = 0; cn < COARSE_N; cn++) {
acc[cm][cn] = fma(rA[cm], rB[cn], acc[cm][cn]);
}
}
}
__syncthreads();
}
// 값 복사
for (int cm = 0; cm < COARSE_M; cm += 1) {
for (int cn = 0; cn < COARSE_N; cn += 1) {
int ty = tidy + TILE_SIZE * cm;
int tx = tidx + TILE_SIZE * cn;
int gidx = col + tx;
int gidy = row + ty;
if (gidx < N && gidy < M) {
C[gidy * N + gidx] = __float2half(acc[cm][cn] * alpha + __half2float(C[gidy * N + gidx]) * beta);
}
}
}
}
// A, B, and C are device pointers
extern "C" void solve(const half* A, const half* B, half* C, int M, int N, int K, float alpha, float beta) {
dim3 threadsPerBlock(TILE_SIZE, TILE_SIZE);
dim3 blocksPerGrid((N + BLOCK_N - 1) / BLOCK_N, (M + BLOCK_M - 1) / BLOCK_M);
matmul<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, M, N, K, alpha, beta);
}
약 1.45ms를 소요하며 SOTA인 0.7371ms에 비해 2배 정도 느리다. 발생했던 문제 중 하나는 테스트시 COARSE_M과 COARSE_N을 (8, 4)로 설정했을 때, shared memory 초과로 문제가 터진 듯 하다. 계산 했을때 공유 메모리 사용량은 4 byte * 32 * 32 * (8 + 4) = 48KB인데 T4의 thread block당 shared memory가 조정을 하지 않았을 떄 48KB로 CUDA 내부 정렬로 인해 fail했을 수 있다고 한다. 이를 해결하기 위해 COARSE_M과 COARSE_N을 (4, 4)로 설정하게 되었다.
여기까지는 쿠다 코어만을 활용하여서 최적화를 진행하였다. 더블 버퍼링, 벡터화 로드 등을 활용하여서 추가적인 최적화가 가능하겠지만, 그런 최적화들을 적용했을 시에 텐서 코어를 활용하고자 한다면 복잡해질 것 같아서, 우선 텐서코어 연산을 추가하고 그후에 적용해보고자 한다.
WMMA api 적용
이 것을 하기전에 여러 예제에서 ptx를 활용하여 mma를 하는 블로그 글들을 많이 봤었다. 하지만 나는 그전에 wmma api를 써본 적이 없으므로 래핑된 api를 먼저 사용해보고 추후에 추가 최적화가 필요하다고 판단했을 시에 ptx mma 명령어 코드로 변환하기로 마음 먹었다.
WMMA api 사용법 정리
#include <mma.h>
using namespace nvcuda;
template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment;
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
void fill_fragment(fragment<...> &a, const T& v);
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);
// ldm = 메모리에서 한 행의 시작부터 다음 행의 시작까지의 원소 개수
// layout_t = 행렬이 메모리에 저장된 방식
// wmma::row_major // 행 우선 (C 스타일)
// wmma::col_major // 열 우선 (Fortran 스타일)
// wmma::mem_row_major // store용 row-major
// wmma::mem_col_major // store용 col-major
wmma::fragments초기화하기wmma::load_matrix_sync같은 함수로 데이터를 fragment에 로드하기wmma::mma_sync로 행렬 곱셈 및 누적 연산 수행하기wmma::store_matrix_sync로 결과를 메모리에 다시 저장하기
WMMA base 코드
#include <cuda_runtime.h>
#include <cuda_fp16.h>
#include <mma.h>
#define WARP_SIZE 32
using namespace nvcuda;
// WMMA T4(Turing) - m16n16k16
// D[16x16] = A[16x16] * B[16x16] + C[16x16]
constexpr int WMMA_M = 16;
constexpr int WMMA_N = 16; // B, C의 열 수
constexpr int WMMA_K = 16; // A의 열 수 = B의 행 수
// 블록당 4x4 = 16개의 warp 배치
// 각 warp은 하나의 16x16 WMMA 타일을 담당
constexpr int WARP_M = 4; // M 방향 warp 수
constexpr int WARP_N = 4; // N 방향 warp 수
// 블록이 처리하는 총 영역 크기
constexpr int BLOCK_M = WMMA_M * WARP_M;
constexpr int BLOCK_N = WMMA_N * WARP_N;
constexpr int BLOCK_K = 32;
constexpr int NUM_THREADS = WARP_M * WARP_N * WARP_SIZE;
__global__ void matmul_wmma(const half* A, const half* B, half* C, int M, int N, int K, float alpha, float beta) {
const int warpId = threadIdx.x / WARP_SIZE; // 스레드가 속한 warp id
const int warpRow = warpId / WARP_N; // 어느 행의 warp인지
const int warpCol = warpId % WARP_N; // 어느 열의 warp인지
// 블록이 담당하는 C 행렬의 시작 좌표
const int blockRowStart = blockIdx.y * BLOCK_M; // M 방향
const int blockColStart = blockIdx.x * BLOCK_N; // N 방향
// warp가 담당하는 16x16 타일의 블록 내 시작 위치
const int warpRowOffset = warpRow * WMMA_M;
const int warpColOffset = warpCol * WMMA_N;
__shared__ half sA[BLOCK_M][BLOCK_K];
__shared__ half sB[BLOCK_K][BLOCK_N];
__shared__ half sC[BLOCK_M][BLOCK_N];
wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> fragA;
wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> fragB;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> acc; // accumulator만 float
wmma::fill_fragment(acc, 0.0f); // 0으로 초기화
// main loop
for (int k = 0; k < K; k += BLOCK_K) {
// load tiles
#pragma unroll
for (int i = 0; i < (BLOCK_M * BLOCK_K) / NUM_THREADS; i++) {
// 선형 인덱스 계산: 각 스레드가 담당할 원소
int idx = threadIdx.x + i * NUM_THREADS;
// 2D 인덱스로 변환 (row-major 순서로 순회)
int row = idx / BLOCK_K; // 0~63
int col = idx % BLOCK_K; // 0~31
// 전역 메모리 좌표
int globalRow = blockRowStart + row;
int globalCol = k + col;
// 경계 체크 후 로드 (범위 밖이면 0)
if (globalRow < M && globalCol < K) {
sA[row][col] = A[globalRow * K + globalCol];
} else {
sA[row][col] = __float2half(0.0f);
}
}
#pragma unroll
for (int i = 0; i < (BLOCK_N * BLOCK_K) / NUM_THREADS; i++) {
int idx = threadIdx.x + i * NUM_THREADS;
int row = idx / BLOCK_N; // 0~31
int col = idx % BLOCK_N; // 0~63
int globalRow = k + row;
int globalCol = blockColStart + col;
if (globalRow < K && globalCol < N) {
sB[row][col] = B[globalRow * N + globalCol];
} else {
sB[row][col] = __float2half(0.0f);
}
}
__syncthreads();
// WMMA 연산
#pragma unroll
for (int wk = 0; wk < BLOCK_K; wk += WMMA_K) {
wmma::load_matrix_sync(fragA, &sA[warpRowOffset][wk], BLOCK_K);
wmma::load_matrix_sync(fragB, &sB[wk][warpColOffset], BLOCK_N);
wmma::mma_sync(acc, fragA, fragB, acc);
}
__syncthreads();
}
if (beta != 0.0f) {
#pragma unroll
for (int i = 0; i < (BLOCK_M * BLOCK_N) / NUM_THREADS; i++) {
int idx = threadIdx.x + i * NUM_THREADS;
int row = idx / BLOCK_N;
int col = idx % BLOCK_N;
int globalRow = blockRowStart + row;
int globalCol = blockColStart + col;
if (globalRow < M && globalCol < N) {
sC[row][col] = C[globalRow * N + globalCol];
} else {
sC[row][col] = __float2half(0.0f);
}
}
__syncthreads();
// Shared → Register: 기존 C fragment 로드
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, half> fragC;
wmma::load_matrix_sync(fragC, &sC[warpRowOffset][warpColOffset], BLOCK_N, wmma::mem_row_major);
// alpha * acc + beta * C 계산
// fragment 내 각 원소에 대해 수행
#pragma unroll
for (int i = 0; i < acc.num_elements; i++) {
acc.x[i] = alpha * acc.x[i] + beta * __half2float(fragC.x[i]);
}
} else {
// beta == 0: alpha 스케일링만 적용
#pragma unroll
for (int i = 0; i < acc.num_elements; i++) {
acc.x[i] *= alpha;
}
}
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, half> fragOut;
#pragma unroll
for (int i = 0; i < acc.num_elements; i++) {
fragOut.x[i] = __float2half(acc.x[i]);
}
wmma::store_matrix_sync(&sC[warpRowOffset][warpColOffset], fragOut, BLOCK_N, wmma::mem_row_major);
__syncthreads();
#pragma unroll
for (int i = 0; i < (BLOCK_M * BLOCK_N) / NUM_THREADS; i++) {
int idx = threadIdx.x + i * NUM_THREADS;
int row = idx / BLOCK_N;
int col = idx % BLOCK_N;
int globalRow = blockRowStart + row;
int globalCol = blockColStart + col;
if (globalRow < M && globalCol < N) {
C[globalRow * N + globalCol] = sC[row][col];
}
}
}
extern "C" void solve(const half* A, const half* B, half* C, int M, int N, int K, float alpha, float beta) {
dim3 blockDim(NUM_THREADS);
dim3 gridDim((N + BLOCK_N - 1) / BLOCK_N, (M + BLOCK_M - 1) / BLOCK_M);
matmul_wmma<<<gridDim, blockDim>>>(A, B, C, M, N, K, alpha, beta);
}
1.30ms(약 1.76배)를 기록하였다. tensor core 사용하는 기본 코드가 warp 단위의 반강제 타일링(?)이 적용된 버전이 cuda core만 사용하는 tiling + thread coarsening 버전보다 10% 정도 더 빨랐다. (연산시에 warp를 기본단위로 보는거가 더 가깝긴 한것 같다.)
사용한 공유 메모리 계산시 BLOCK_K=32, BLOCK_M=64, BLOCK_N=64일때 (32 * 64 + 64 * 64 + 32 * 64) * 2byte = 16KB가 사용되었다. 제한에 아직 여유가 있기도하고 WARP_M, WARP_N에 대해서 타일링을 적용하면 로드된 레지스터의 값을 재활용할 수 있으므로 성능의 이득이 있을 것이라 판단하여 적용해보기로 하였다.
WMMA API + tiling
#include <cuda_runtime.h>
#include <cuda_fp16.h>
#include <mma.h>
using namespace nvcuda;
constexpr int WARP_SIZE = 32;
// WMMA T4(Turing) - m16n16k16
// D[16x16] = A[16x16] * B[16x16] + C[16x16]
constexpr int WMMA_M = 16;
constexpr int WMMA_N = 16; // B, C의 열 수
constexpr int WMMA_K = 16; // A의 열 수 = B의 행 수
constexpr int TILE_M = 2; // M 방향 타일 수 (warp)
constexpr int TILE_N = 2; // N 방향 타일 수 (warp)
// 블록당 4x4 = 16개의 warp 배치
// 각 warp은 하나의 16x16 WMMA 타일을 담당
constexpr int WARP_M = 4; // M 방향 warp 수
constexpr int WARP_N = 4; // N 방향 warp 수
// 블록이 처리하는 총 영역 크기
constexpr int BLOCK_M = WMMA_M * TILE_M * WARP_M;
constexpr int BLOCK_N = WMMA_N * TILE_N * WARP_N;
constexpr int BLOCK_K = 32;
constexpr int NUM_THREADS = WARP_M * WARP_N * WARP_SIZE;
__global__ void matmul_wmma(const half* A, const half* B, half* C, int M, int N, int K, float alpha, float beta) {
const int warpId = threadIdx.x / WARP_SIZE; // 스레드가 속한 warp id
const int warpRow = warpId / WARP_N; // 어느 행의 warp인지
const int warpCol = warpId % WARP_N; // 어느 열의 warp인지
// 블록이 담당하는 C 행렬의 시작 좌표
const int blockRowStart = blockIdx.y * BLOCK_M; // M 방향
const int blockColStart = blockIdx.x * BLOCK_N; // N 방향
// warp가 담당하는 16x16 타일의 블록 내 시작 위치
const int warpRowStart = warpRow * WMMA_M * TILE_M;
const int warpColStart = warpCol * WMMA_N * TILE_N;
__shared__ half sA[BLOCK_M][BLOCK_K];
__shared__ half sB[BLOCK_K][BLOCK_N];
__shared__ half sC[BLOCK_M][BLOCK_N];
wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> fragA[TILE_M]; // (bM) * bK
wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> fragB[TILE_N]; // bK * (bN)
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> acc[TILE_M][TILE_N]; // accumulator만 float
#pragma unroll
for (int tm = 0; tm < TILE_M; tm++) {
#pragma unroll
for (int tn = 0; tn < TILE_N; tn++) {
wmma::fill_fragment(acc[tm][tn], 0.0f);
}
}
// main loop
for (int k = 0; k < K; k += BLOCK_K) {
// load tiles
#pragma unroll
for (int i = 0; i < (BLOCK_M * BLOCK_K) / NUM_THREADS ; i++) {
int idx = threadIdx.x + i * NUM_THREADS;
int row = idx / BLOCK_K;
int col = idx % BLOCK_K;
int globalRow = blockRowStart + row;
int globalCol = k + col;
if (globalRow < M && globalCol < K) {
sA[row][col] = A[globalRow * K + globalCol];
} else {
sA[row][col] = __float2half(0.0f);
}
}
#pragma unroll
for (int i = 0; i < (BLOCK_N * BLOCK_K) / NUM_THREADS; i++) {
int idx = threadIdx.x + i * NUM_THREADS;
int row = idx / BLOCK_N;
int col = idx % BLOCK_N;
int globalRow = k + row;
int globalCol = blockColStart + col;
if (globalRow < K && globalCol < N) {
sB[row][col] = B[globalRow * N + globalCol];
} else {
sB[row][col] = __float2half(0.0f);
}
}
__syncthreads();
// WMMA 연산
#pragma unroll
for (int bk = 0; bk < BLOCK_K; bk += WMMA_K) {
#pragma unroll
for (int tm = 0; tm < TILE_M; tm++) {
int aRow = warpRowStart + tm * WMMA_M;
wmma::load_matrix_sync(fragA[tm], &sA[aRow][bk], BLOCK_K);
}
#pragma unroll
for (int tn = 0; tn < TILE_N; tn++) {
int bCol = warpColStart + tn * WMMA_N;
wmma::load_matrix_sync(fragB[tn], &sB[bk][bCol], BLOCK_N);
}
#pragma unroll
for (int tm = 0; tm < TILE_M; tm++) {
#pragma unroll
for (int tn = 0; tn < TILE_N; tn++) {
wmma::mma_sync(acc[tm][tn], fragA[tm], fragB[tn], acc[tm][tn]);
}
}
}
__syncthreads();
}
// epilogue
constexpr int LOAD_C = (BLOCK_M * BLOCK_N) / NUM_THREADS;
if (beta != 0.0f) {
#pragma unroll
for (int i = 0; i < LOAD_C; i++) {
int idx = threadIdx.x + i * NUM_THREADS;
int row = idx / BLOCK_N;
int col = idx % BLOCK_N;
int globalRow = blockRowStart + row;
int globalCol = blockColStart + col;
if (globalRow < M && globalCol < N) {
sC[row][col] = C[globalRow * N + globalCol];
} else {
sC[row][col] = __float2half(0.0f);
}
}
__syncthreads();
#pragma unroll
for (int tm = 0; tm < TILE_M; tm++) {
#pragma unroll
for (int tn = 0; tn < TILE_N; tn++) {
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, half> fragC;
wmma::load_matrix_sync(fragC, &sC[warpRowStart + tm * WMMA_M][warpColStart + tn * WMMA_N],
BLOCK_N, wmma::mem_row_major);
#pragma unroll
for (int i = 0; i < acc[tm][tn].num_elements; i++) {
acc[tm][tn].x[i] = alpha * acc[tm][tn].x[i] + beta * __half2float(fragC.x[i]);
}
}
}
} else {
#pragma unroll
for (int tm = 0; tm < TILE_M; tm++) {
#pragma unroll
for (int tn = 0; tn < TILE_N; tn++) {
#pragma unroll
for (int i = 0; i < acc[tm][tn].num_elements; i++) {
acc[tm][tn].x[i] *= alpha;
}
}
}
}
// register to smem
#pragma unroll
for (int tm = 0; tm < TILE_M; tm++) {
#pragma unroll
for (int tn = 0; tn < TILE_N; tn++) {
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, half> fragOut;
#pragma unroll
for (int i = 0; i < acc[tm][tn].num_elements; i++) {
fragOut.x[i] = __float2half(acc[tm][tn].x[i]);
}
wmma::store_matrix_sync(&sC[warpRowStart + tm * WMMA_M][warpColStart + tn * WMMA_N], fragOut, BLOCK_N, wmma::mem_row_major);
}
}
__syncthreads();
// save result
#pragma unroll
for (int i = 0; i < LOAD_C; i++) {
int idx = threadIdx.x + i * NUM_THREADS;
int row = idx / BLOCK_N;
int col = idx % BLOCK_N;
int globalRow = blockRowStart + row;
int globalCol = blockColStart + col;
if (globalRow < M && globalCol < N) {
C[globalRow * N + globalCol] = sC[row][col];
}
}
}
extern "C" void solve(const half* A, const half* B, half* C, int M, int N, int K, float alpha, float beta) {
dim3 blockDim(NUM_THREADS);
dim3 gridDim((N + BLOCK_N - 1) / BLOCK_N, (M + BLOCK_M - 1) / BLOCK_M);
matmul_wmma<<<gridDim, blockDim>>>(A, B, C, M, N, K, alpha, beta);
}
전체 기록적인 측면에서 0.7371ms -> 0.7174ms로 2.67% 정도를 줄여서 1등을 달성하였다. tiling을 안한 wmma api 사용 버전과 비교를 해보아도 무려 1.8배나 빠른 편이다. tiling의 크기가 크지 않아서 크게 개선되지 않을 것이라 판단했는데 생각보다 컸다.
더 해볼 만한 것들
위에서 언급한 ptx를 직접 쓰는 옵션, 더블 버퍼링, 벡터화된 로드를 적용하지 않고도 1등을 기록할 수 있었다. 추후에 누군가가 손쉽게 내 기록을 넘으면 추가 최적화를 적용해볼 예정이다. 우선은 내 목표를 달생했으니 A100 GPU에 도전하려고 한다.