pmpp lecture 06 performance considerations 요약
source: Lecture 06 - Performance Considerations
Today
- DRAM 아키텍쳐 리뷰
- more performance optimizations
Performance 최적화 방법들
- 점유율을 극대화하기 위해 리소스 사용량을 조절함
- 블록당 스레드 수, 블록당 공유 메모리 크기, 스레드당 레지스터 수
- 제어 분기를 최소화하여 SM의 효율성을 늘림
- 데이터 재사용을 늘리기 위해 공유 메모리 타일링 사용
- Memory coalescing (메모리 병합)
- 인접한 메모리 주소에 접근하는 여러 스레드의 요청을 하나의 트랜잭션으로 합치는 최적화
- Thread coarsening (스레드 조대화)
- 스레드 수를 줄이고 각 스레드가 더 많은 작업을 수행하도록 하는 최적화
DRAM Cell
- DRAM Cell은 전하를 저장하는 일종의 capacitor와 데이터를 읽고 쓸수 있게 해주는 3상 소자로 구성됨
- 활성화 하면 해당 값을 읽기 위해 capacitor가 방전됨.
- value가 1이면 방전이 되고 방전이 감지될것임.
- value가 0이면 방전이 되지 않고 방전이 감지되지 않을것임.
DRAM Array
- 여러개의 DRAM Cell이 column wire에 연결되어 있음.
- 어느 시점에서든 모든 것이 와이어에 의해 연결되어 있기 때문에 하나만 읽을 것임
- DRAM bank는 2차원 배열의 DRAM cell로 구성되어 있고 한행을 활성화하여 컬럼을 읽을 수 있음.
- DRAM을 읽는 동안 값이 파괴되어 다시 써야함. DRAM이 느린 이유임.
DRAM Bank
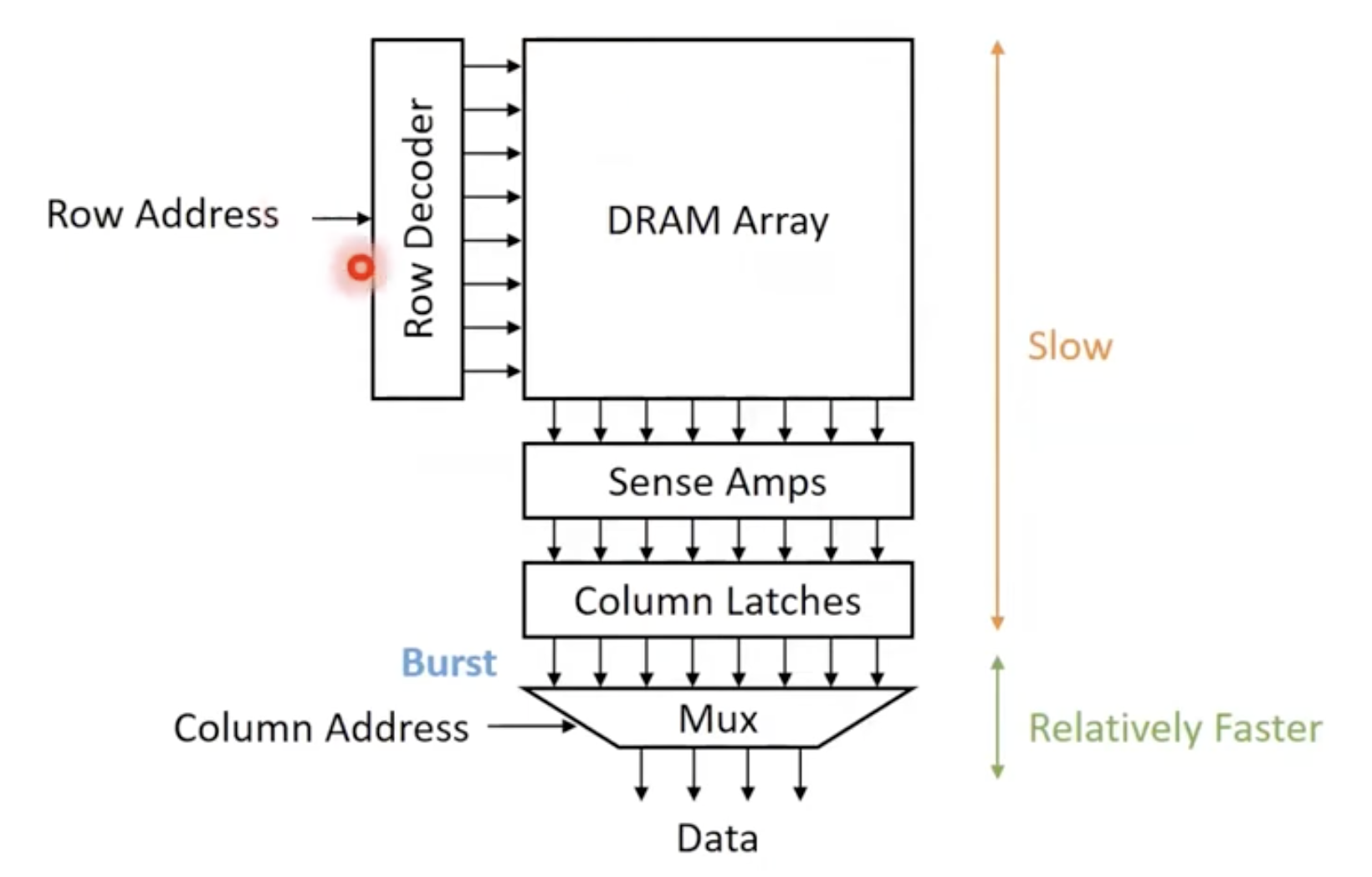
- Row Decoder에 Row Address를 제공함.
- Row Decoder는 우리가 원하는 행을 결정하고 이 출력 중 하나를 1로 설정하고 나머지는 0으로 설정함.
- 그리고 이 디코딩된 신호를 DRAM 뱅크로 전달함.
- DRAM 뱅크는 이행의 모든 셀이 방전될 것이고, 값들이 나올 것임.
- 이 값들은 감지 증폭기(Sense amplifier)로 전달되어 변화를 감지하여 capacitor에 값이 0인지 1인지 감지함.
- 그리그 전하의 변화를 column latch에 저장함.
- 이것들은 값을 읽더라도 값을 유지함.
- 우리가 읽은 값을 다시 사용하는데 쓸 수 있음.
- capacitor에 있던 value는 값이 파괴된다고 함(방전되어서 그런듯)
- 행은 보통 일반적인 요청 크기보다 큼. 주소에는 column adress 부분이 있어서 멀티플렉서로 전달되어 행의 데이터 부분을 선택함.
- 읽은 전체 값을 DRAM Burst라고 부름.
- 가장 느린 부분이 어디일까?
- DRAM Array, Sense Amps, Column Latches가 크고 오래 걸림.
- Multiplexer는 비교적 빠름
DRAM Burst
- 다른 burst의 데이터에 접근하는 경우 (Row address가 다른 경우)
- DRAM Array에 다시 접근해야함.
- 동일한 burst의 데이터에 접근하는 경우
- DRAM Arrray에 접근할 필요 없이 multiplexer만 변경하면 됨.
- 훨씬 시간이 적게 걸림
Memory Coalescing
- 같은 워프에 있는 스레드들이 배열에서 연속적인 데이터를 읽는다면, 그 데이터는 같은 DRAM burst에 있을 가능성이 높음.
- 이러한 접근은 결합되어 한번의 지시로 처리될 수 있음.
- 하나의 DRAM transaction으로 처리될 수 있음.
- memory coalescing이라고 함.
- 동일한 버스트에 없는 접근 위치가 있다면, 이 접근은 결합될 수 없음.
- 여러번의 트랜잭션이 필요할꺼고 더 오래 걸릴 것임.
- 때때로 사람들이 memory divergence라고 부름.
Memory Coalescing Example
- Vector addition
- x, y, z로의 접근이 coalesced임.
- thread 0~ 31까지가 각각 x, y, z의 0~ 31번째 요소에 접근하고 warp에 대해 한 트랜잭션으로 일어남.
- x, y, z로의 접근이 coalesced임.
- Matrix-matrix multiplication
- A는 행을 기준으로 B는 열을 기준으로 접근함.
Multiple DRAM Banks
- 여러가지 이유로 DRAM은 여러 개의 bank를 가지고 있음.
- 거대한 DRAM array를 제조하는 것이 실현 불가능함.
- DRAM에 대해 접근할 때 병렬성을 확보할 수 있음.
- 한 DRAM이 서빙하는동안 다른 DRAM은 요청을 찾는 것을 하고 있음.
- 이렇게 하면 메모리에서의 Latency hiding이 가능함
- 동시에 많은 메모리 뱅크에서 데이터를 읽는다면, 지연시간을 겹치게 하려면 많은 메모리 접근을 서비스에 제공해야함.
- 많은 스레드가 동시에 실행되고 동시에 데이터를 요청하여 DRAM뱅크를 바쁘게 해야함.
- 한 SM에서 더 많은 워프를 실행하고 싶음.
- 코어에서 지연시간을 숨기는 것과 비슷한 아이디어임
- 많은 스레드가 동시에 실행되고 동시에 데이터를 요청하여 DRAM뱅크를 바쁘게 해야함.
Thread Granularity(쓰레드 세분성)
- 우리가 사용해 온 병렬화 접근 방식은 스레드가 가능한 한 세분화(fine-grain) 되는 것이였음
- 병렬 처리의 가장 작은 단위에 스레드를 할당한다는 것
- 벡터 덧셈을 할때 각 스레드가 하나의 벡터 요소를 계산하게 했음.
- RGB를 gray로 바꿀때 모든 출력픽셀에 할당했음.
- 행렬곱에서는 출력행렬의 모든 요소에 할당했음.
- 병렬 처리의 가장 작은 단위에 스레드를 할당한다는 것
- 작게하는 것의 장점은 무엇인가?
- 하드웨어에 가능한 많은 스레드를 제공하여 리소스를 최대한 활용할 수 있음.
- GPU가 지원하는 것보다 많은 스레드를 제공하면, 하드웨어는 낮은 오버헤드로 작업을 직렬화 할 수 있음.
- 새로운 GPU가 출시되고 그 GPU가 더 많은 리소스를 가지고 있다면 하드웨어는 다시 코드를 작성할 필요 없이 더 많은 병렬성을 제공할 수 있음.
- transparent scalability라고 함.
- 하드웨어 가능한 한 많은 스레드를 제공하면 유연성이 생김.
- 하드웨어에 가능한 많은 스레드를 제공하여 리소스를 최대한 활용할 수 있음.
- 단점은 무엇인가?
- 스레드간 중복적으로 수행되는 공통 작업이 있다면 이는 불필요한 오버헤드가 될 수 있음.
- 스레드가 병렬적으로 작업될때는 괜찮음.
- 직렬화되어 실행되고 있다면 문제가 될 수 있음.
- 적절한 직렬화를 통해 추가적인 최적화를 할 수 있음.
- 스레드간 중복적으로 수행되는 공통 작업이 있다면 이는 불필요한 오버헤드가 될 수 있음.
Optimizing Tiled Matrix-Matrix Multiplication
- 매번 A, B 블록의 새로운 타일을 가져오는 대신 B 블록만 추가적으로 가져와서 A 블록의 타일을 재사용할 수 있음.
- coarsening factor는 각 스레드가 원래는 하나를 담당했던 병렬 처리 단위를 얼마나 많이 담당할 것인가를 나타냄.
- coarsening factor 값에 따라 결과가 나빠질 수 있음.
- thread coarsening은 스레드에 병렬처리 프로세스를 할당하는 최적화 기법임.
- thread는 coarse-grain 해짐.
- 장점:
- 병렬화에 드는 비용을 줄여줌.
- 행렬곱에서 memory 로드 중복을 줄였음.
- 다른 예제에서는 중복된 연산을 줄일 수도 있음.
- 동기화나 분기를 줄일수도 있음.
- 병렬화에 드는 비용을 줄여줌.
- 단점:
- coarsening factor가 너무 높으면 리소스를 제대로 활용하지 못할 수 있음.
- 장치마다 다른 최적의 factor가 있음.
- 더이상 transparent scalability를 얻지 못함
- 스레드가 더 많은 리소스를 사용해야함. 너무 많이 사용하면 제한될 수 있음.
- coarsening factor가 너무 높으면 리소스를 제대로 활용하지 못할 수 있음.
일반적인 최적화 기법 체크리스트
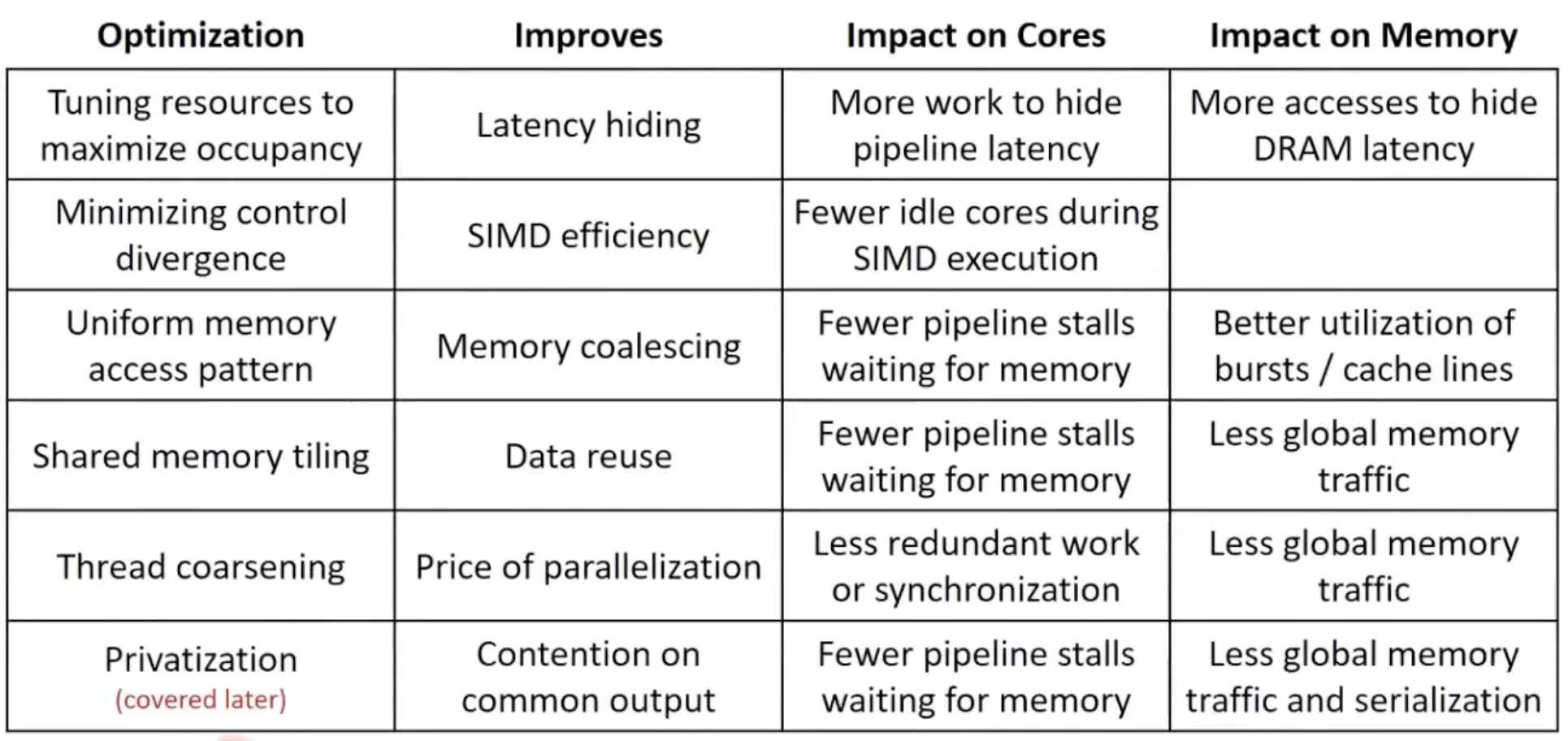
최적화 사이의 긴장감 (Tensions Between Optimizations)
- 점유율을 극대화하는것과 동시에 캐시의 스레싱을 제어하는 것 사이의 긴장감
- 때때로 점유율이 너무 높고 스레드들이 너무 많은 메모리를 사용하고 너무 많은 스레드를 가지면
- 이 스레드들이 캐시를 놓고 경쟁하기 시작하고 서로의 데이터를 쫓아낼 수 있음.(thrashing)
- 공유 메모리 타일링
- 공유 메모리를 많이 사용하면 더 많은 데이터를 재사용가능함.
- 하지만 너무 많이 사용하면 스레드를 완전히 활용할 만큼 충분한 공유 메모리를 가지고 있지 않기 때문에 점유율이 제한 될 수 있음
- 쓰레드 코스닝(coarsening)
- coarsening이 중복 작업을 줄여주지만 너무 많이 하면 점유율을 제한하게 될 수 있음.
- 따라서 최상의 절충안을 달성하는 최적의 지점을 찾는 것이 중요하고 병목현상(bottleneck)이 무엇인지 아는 것도 중요함
- 잘못된 것을 고치고 싶지 않아서.
- 애플리케이션에 따라 병목현상이 다를 수 있지만 장치에 따라 다를 수도 있음.
- 최적화를 적용할때 병목현상을 완화하기 위해 한 자원을 다른 자원과 교환함.
- 잘못된 최적화를 적용하면 잘못된 리소스를 최적화하고 성능향상을 얻지 못하거나 더 나빠질 수 있음.