pmpp lecture 10 reduction 요약
Source: Lecture 10 - Reduction
Reduction
- 입력 값의 집합을 하나의 출력 값으로 줄이는 것.
- sum, product, min, max
- 리덕션 연산은 일반적으로
- 결합 연산(Associative) ex) (a + b) + c = a + (b + c)
- 교환 연산(Commutative) ex) a + b = b + a
- 잘 정의된 항등원을 가짐(well-define identity value)
- 일반적으로 줄일 요소가 없을 때 얻는 값.
- sum: 0, product: 1
- 덧셈에 대해서 다룸. 곱셈과 같은 다른 reduction 연산에 대해서도 확장됨.
- Reduction(축약)은 개념이고 Fold(접기)는 구현 방법 중 하나임.
Sequential Reduction
- loop를 만듬.
- 합계를 0으로 초기화하고 i를 0부터 n까지 덧셈함.
- 일반적으로
acc = IDENTITY; // 항원으로 초기화
for (i = 0 ; i < N; ++i) { // 0부터 N까지 반복
acc = f(acc, input[i]); // 배열을 반복하면서 어떤 연산을 적용함.
}
- 여기서 누적 때문에 루프 반복 전체에 걸쳐서 의존성이 있음.
Parallel Reduction
- 8개의 요소를 가진 배열이 있다면, 모든 스레드가 각 단계에서 두 요소를 더하도록 하는 것
- 4개의 스레드를 만들 것이고 이 4개의 스레드는 두개의 요소를 병렬로 더함.
- 합산해야 할 요소의 수를 절반으로 줄인 것임.
- 4개의 요소가 남음.
- 2개의 스레드를 사용하여 2개의 부분합을 만들고
- 마지막으로 하나의 스레드를 사용하여 두 요소를 병렬로 더해 최종 결과를 얻을 수 있음.
- reduction tree라고 부름. 실제 데이터 구조를 구축하는 것은 아니고 계산 패턴일 뿐임.
- n개의 요소가 있다면 몇단계가 필요할까?
- log2(n) 단계가 필요함.
- 절반의 스레드가 매 단계마다 drop out 됨.
- 각 단계마다 스레드간에 동기화할 수 있어야 함.
- 같은 블록 내의 스레드는 동기화 가능하지만 다른 블록의 스레드는 동기화가 불가능함.
- 따라서 단일 블록 내에서 리덕션을 수행하는 경우 이 작업을 수행할 수 있음.
- 여러 블록에 걸쳐 리덕션 트리를 수행하는 것은 조금 더 까다로움
- 그래서 GPU에서 리덕션을 수행하는 일반적인 방법은 세그먼트 리덕션이라는것을 사용하는 것임.
Segment Reduction
- 스레드는 단계별로 동기화해야 함.
- 다른 블록간에는 스레드를 동기화할 수 없음.
- 솔루션
- 모든 스레드는 입력의 한 세그먼트를 축소하여 부분 합계를 생성함.
- 그리고 나중에 함께 부분 합 배열을 reduce 할것임.
- 일반적으로 이 부분합 배열은 input array보다 훨씬 작음.
- 재귀적으로 새로운 reduction kernel을 시작하거나
- atomic operation을 사용하여 하나의 누산기에 원자적으로 누적하는 것.
- 그냥 CPU에서 더하는 것 (충분히 작아서 병렬화할 가치가 없을 수 있음)
Reduction Tree (Per Block)
- 한 가지 방법은 입력에서 일정 간격 요소마다 스레드를 할당하는 것
- 실제로 스레드가 담당하는 요소가 스레드 블록 크기의 두배임.
- 스레드는 자신의 값을 옆에 있는 값에 더하게 됨. 그러면 요소가 절반으로 줄음.
- 더해진 요소 이웃끼리 또 더해줌. 그러면 한 쓰레드는 필요 없어져서 drop out하면 됨.
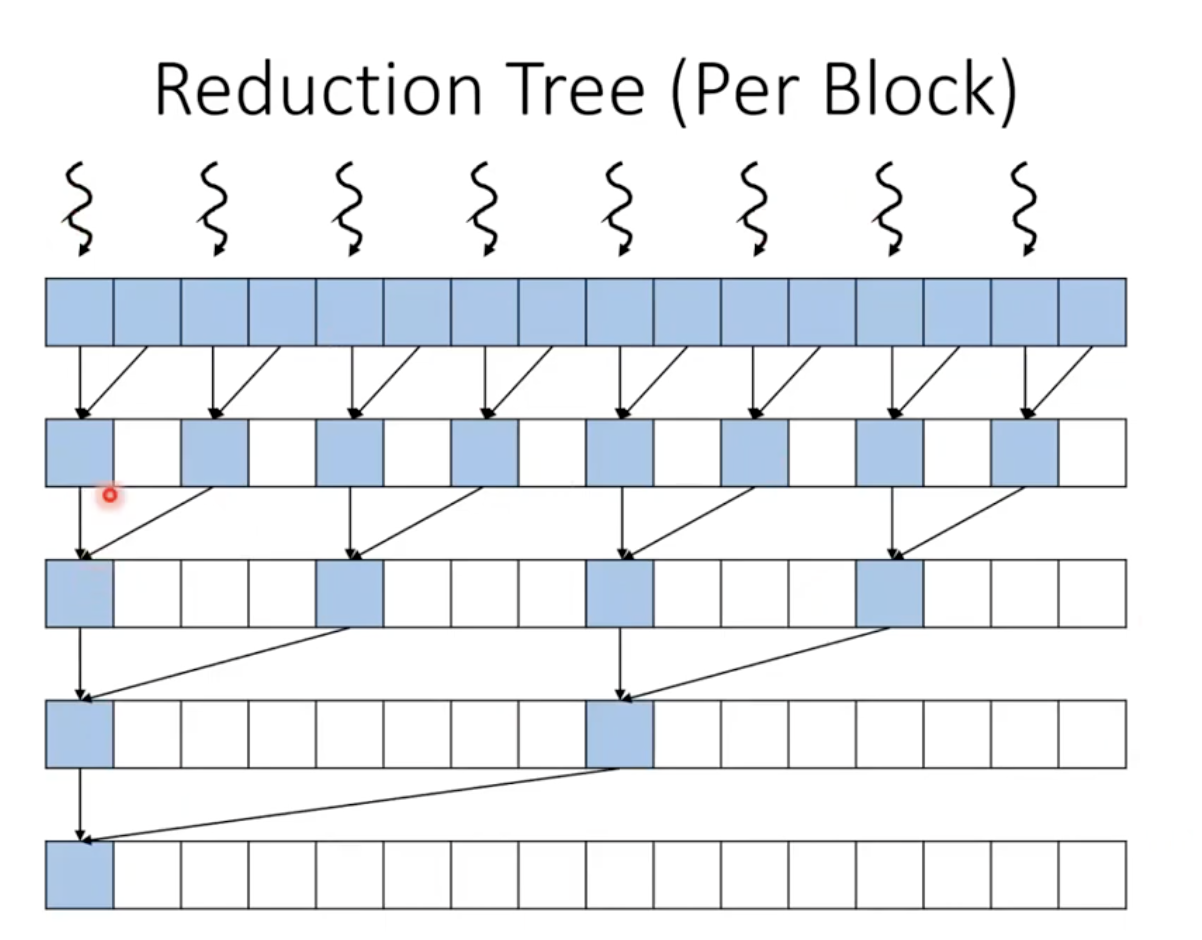
- Q&A: tree의 마지막 지점에서는 활용률이 너무 낮아서 자원을 많이 낭비하는 것 아닌가
- 나중에 이것들을 최적화할 방법들을 다룰 예정
__global__ void reduce_kernel(float* input, float* partialSums, unsigned int N) {
unsigned int segment = (blockIdx.x * blockDim.x) * 2;
unsigned int i = segment + threadIdx.x * 2;
for (unsigned int stride = 1; stride <= BLOCK_DIM; stride *= 2) {
if (threadIdx.x % stride == 0) {
input[i] += input[i + stride];
}
__syncthreads();
}
if (threadIdx.x == 0) {
partialSums[blockIdx.x] = input[segment];
}
}
- reduction의 순차적 특성 때문에 CPU 대비해서 큰 성능 향상을 기대하면 안됨.
Reduction Code 관찰
- 더 최적화 가능한 방법이 뭐가 있을까?
- 글로벌 메모리 접근이 많음.
- 블록에서 사용하는 스레드 수가 반씩 줄어들고 있음.
- 스레드가 SIMD 모델에 의해 계산이 필요하지 않을 때에도 계산하고 있음.
- 실행 리소스를 소비하지만 아무것도 하지 않음. 따라서 control divergence가 발생함.
- memory coalescing
- 같은 워프 내의 스레드가 전역 메모리에서 데이터를 접근하기를 원함.
- 서로 인접해 있어야 메모리 접근을 합칠 수 있음.
- 트리를 내려갈수록 접근은 합쳐지지 않고 점점 나빠짐.
Coalescing and Minimizing Control divergence

- 배열의 매번 일정한 간격의 다른 요소에 스레드를 할당하는 대신 앞의 반에 스레드를 할당함.
- 그러면 요소들이 합쳐질때 왼쪽으로 값이 몰려서 coalescing이 가능해짐.
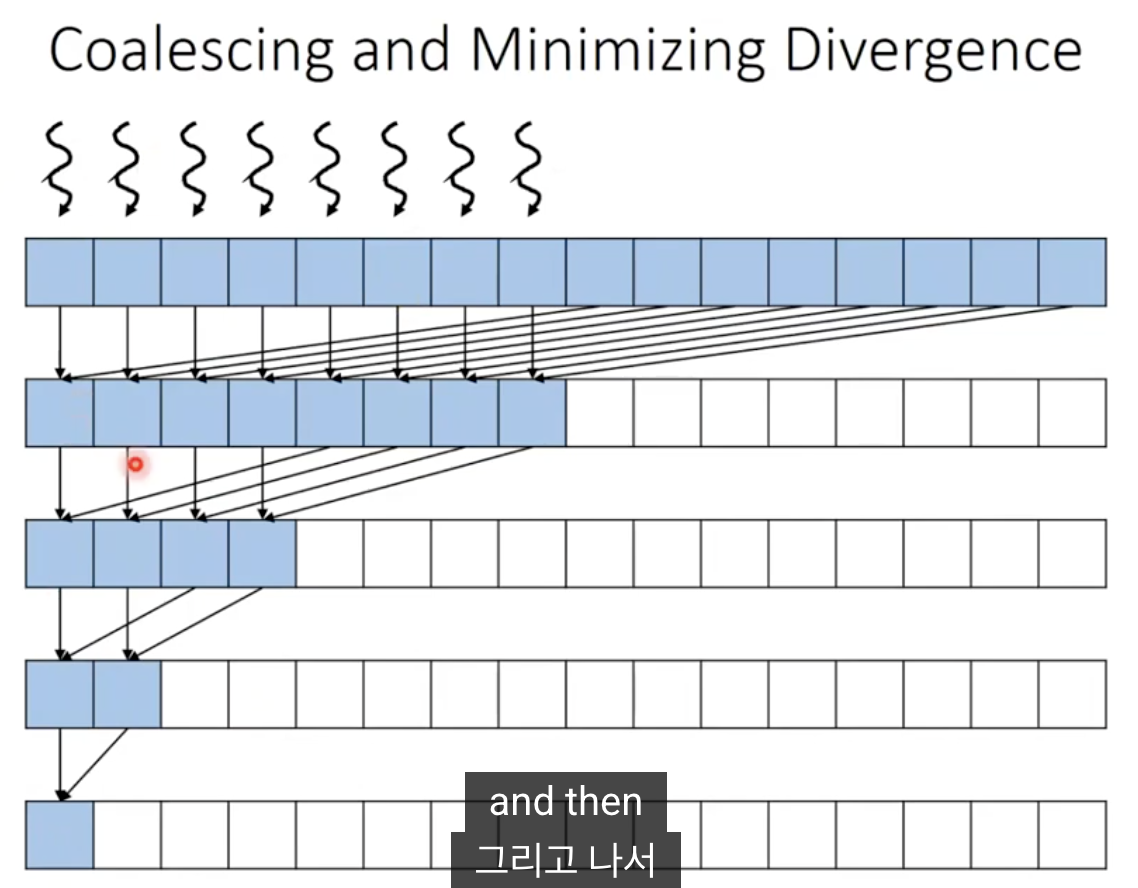
__global__ void reduce_kernel(float* input, float* partialSums, unsigned int N) {
unsigned int segment = (blockIdx.x * blockDim.x) * 2;
unsigned int i = segment + threadIdx.x;
for (unsigned int stride = BLOCK_DIM; stride > 0; stride /= 2) {
if (threadIdx.x < stride) {
input[i] += input[i + stride];
}
__syncthreads();
}
if (threadIdx.x == 0) {
partialSums[blockIdx.x] = input[segment];
}
}
- CPU time: 21.241 ms
- 최적화 전 Kernel time: 3.796 ms, GPU time: 21.708 ms
- 최적화 후 Kernel time: 2.752 ms, GPU time: 20.560 ms
- 제어 분기를 없애고 메모리 coalescing을 최적화함으로써 상당한 개선이 이루어짐.
- 일찍 warp를 drop out 시킬 수 있음.

Data Reuse Using Shared Memory
- 실제로 특정 값이 재사용되지는 않음.
- 이러한 값을 포함하는 메모리 위치는 실제로 재사용됨.
- 공유 메모리에 먼저 저장한 다음 리덕션 트리를 공유 메모리에서 수행함으로써 최적화 가능함.
- 또한 입력값 수정을 피할 수 있음.
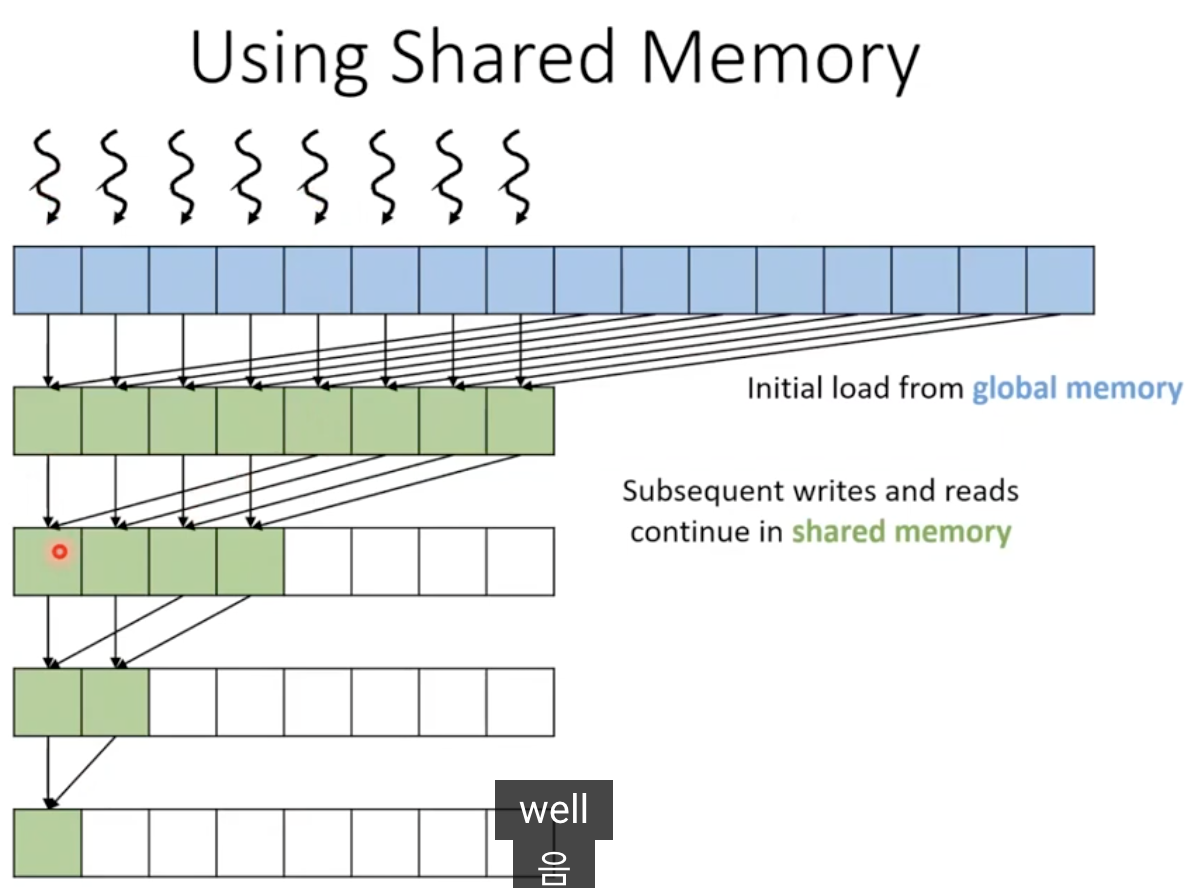
__global__ void reduce_kernel(float* input, float* partialSums, unsigned int N) {
unsigned int segment = (blockIdx.x * blockDim.x) * 2;
unsigned int i = segment + threadIdx.x;
__shared__ float input_s[BLOCK_DIM];
input_s[threadIdx.x] = input[i] + input[i + BLOCK_DIM];
__syncthreads();
for (unsigned int stride = BLOCK_DIM / 2; stride > 0; stride /= 2) {
if (threadIdx.x < stride) {
input_s[threadIdx.x] += input_s[threadIdx.x + stride];
}
__syncthreads();
}
if (threadIdx.x == 0) {
partialSums[blockIdx.x] = input_s[0];
}
}
// 실행 결과 2.15ms kernel time
Thread Coarsening
- 하드웨어가 리소스보다 더 많은 스레드 블록을 가지고 있을때 하드웨어가 일반적으로 하는 일은 스레드 작업을 직렬화 하는 것
- 병렬화에 대한 대가를 치르고 있다면, 병렬화에 드는 비용을 줄이는것
- 하드웨억사 스레드 블록을 직렬화하도록 두는 대신 코드에서 스레드 블록을 직렬화 함.
- 또는 스레드 블록이 여러 스레드 블록에 대한 작업을 수행하도록 함.
- 여기서 병렬화에 대해 지불하는 대가는 무엇인가?
- control divergence = 일부 스레드는 쓸모없게 되는 것
- synchronization
- 사용 가능한 블록과 리소스가 훨씬더 많은 경우 coarsen 함으로써 병렬화에 대한 대가를 줄일 수 있음.
Thread Coarsening 적용
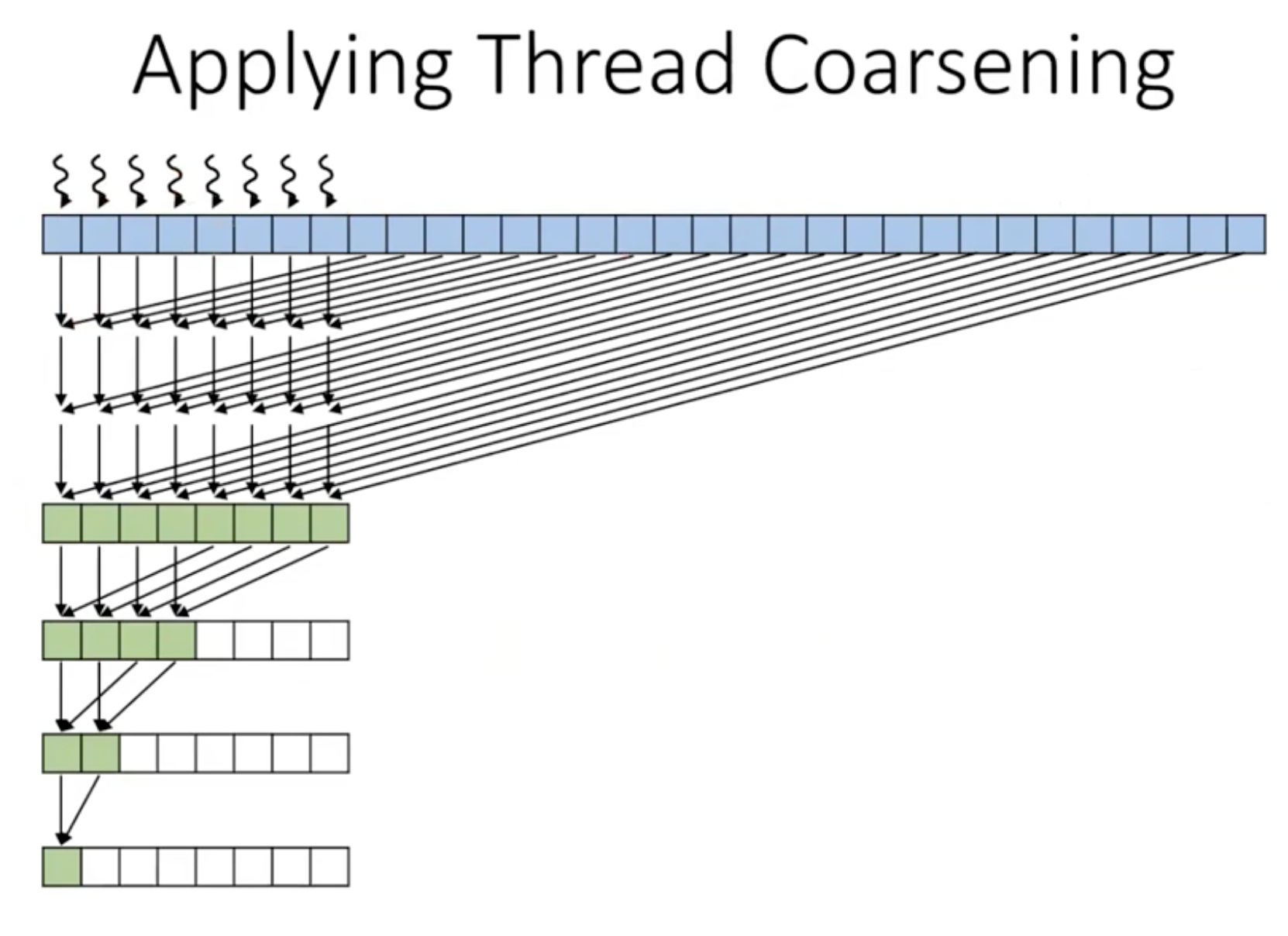
#define BLOCK_DIM 1024
#define COARSE_FACTOR 4
__global__ void reduce_kernel(float* input, float* partialSums, unsigned int N) {
unsigned int segment = (blockIdx.x * blockDim.x) * 2 * COARSE_FACTOR;
unsigned int i = segment + threadIdx.x;
__shared__ float input_s[BLOCK_DIM];
float sum = 0.0f;
for (unsigned int tile = 0; tile < COARSE_FACTOR; ++tile) {
if (i + tile * BLOCK_DIM < N) {
sum += input[i + tile * BLOCK_DIM];
}
}
input_s[threadIdx.x] = sum;
__syncthreads();
for (unsigned int stride = BLOCK_DIM / 2; stride > 0; stride /= 2) {
if (threadIdx.x < stride) {
input_s[threadIdx.x] += input_s[threadIdx.x + stride];
}
__syncthreads();
}
if (threadIdx.x == 0) {
partialSums[blockIdx.x] = input_s[0];
}
}
// 실행 결과 0.677ms
Coarsening 강점
- 블록들이 병렬로 실행된 경우
- log(N) 단계가 필요하고 log(N) 동기화가 필요함.
- 블록이 C만큼의 factor로 하드웨어 동기화된 경우
- C * log(N) 단계가 필요하고 C * log(N) 동기화가 필요함.
- 블록을 C만큼으로 coarsening 시키면
- 2 * (C - 1) + log (N) 단계가 필요하고, log(N) 동기화가 필요함.