pmpp lecture 11 Kogge-Stone scan 요약
Source: Lecture 11 - Scan (Kogge Stone)
Today
- Parallel patterns: scan
- Kogge-Stone method
- Optimization: double-buffering
Scan
- 입력 배열 [x0, x1,..., xn-1]까지를 취하고 결합 연산을 취함
- 출력 배열 [y0, y1,..., yn-1]
- inclusive scan(포괄적 스캔)
- yi = x0 + x1 + ... + xi
- exclusive scan(배타적 스캔)
- yi = x0 + x1 + ... + xi-1
- inclusive scan(포괄적 스캔)
Scan Example
- Addition example
- 입력: [3, 6, 7, 4, 8, 2, 1, 9]
- inclusive scan: [3, 9, 16, 20, 28, 30, 31, 40] - 해당 요소 포함
- exclusive scan: [0, 3, 9, 16, 20, 28, 30, 31] - 해당 요소 포함 안함
Sequential Scan
// inclusive scan
output[0] = input[0];
for (int i = 1; i < n; i++) {
output[i] = f(output[i-1], input[i]);
}
// exclusive scan
output[0] = IDENTITY;
for (int i = 1; i < n; i++) {
output[i] = f(output[i-1], input[i-1]);
}
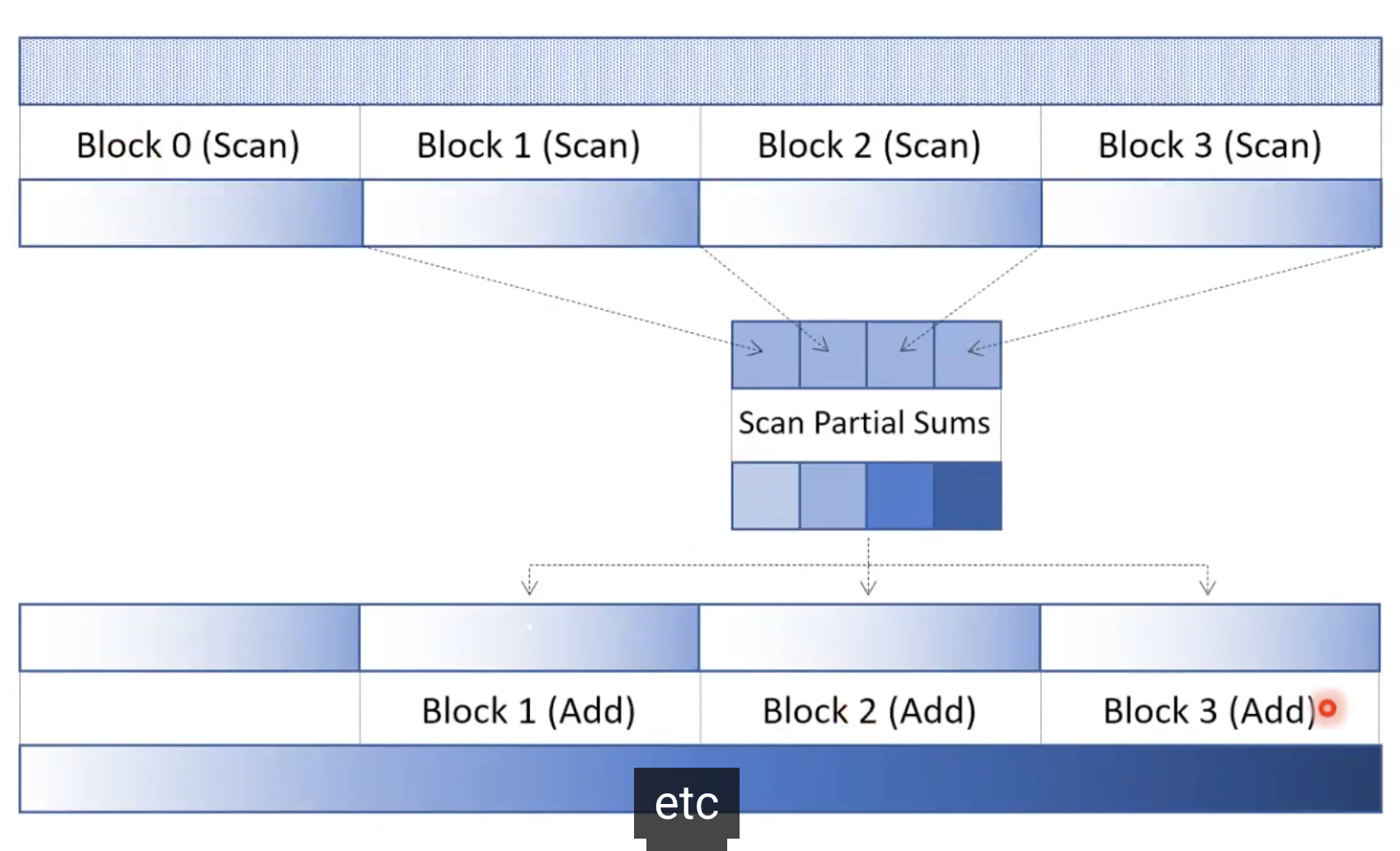
Segmented Scan
- reduction과 비슷하게 병렬로 스캔을 할때 스레드 간에 동기화를 해야함. 일반적으로 분할된 스캔을 함.
- solution: segmented scan(hierarchical scan)
- 모든 스레드 블록은 segment를 스캔함.
- 부분합계를 스캔한 다음, 부분 합계를 기반으로 세그먼트를 업데이트함.
Kogge-Stone Parallel (Inclusive) Scan
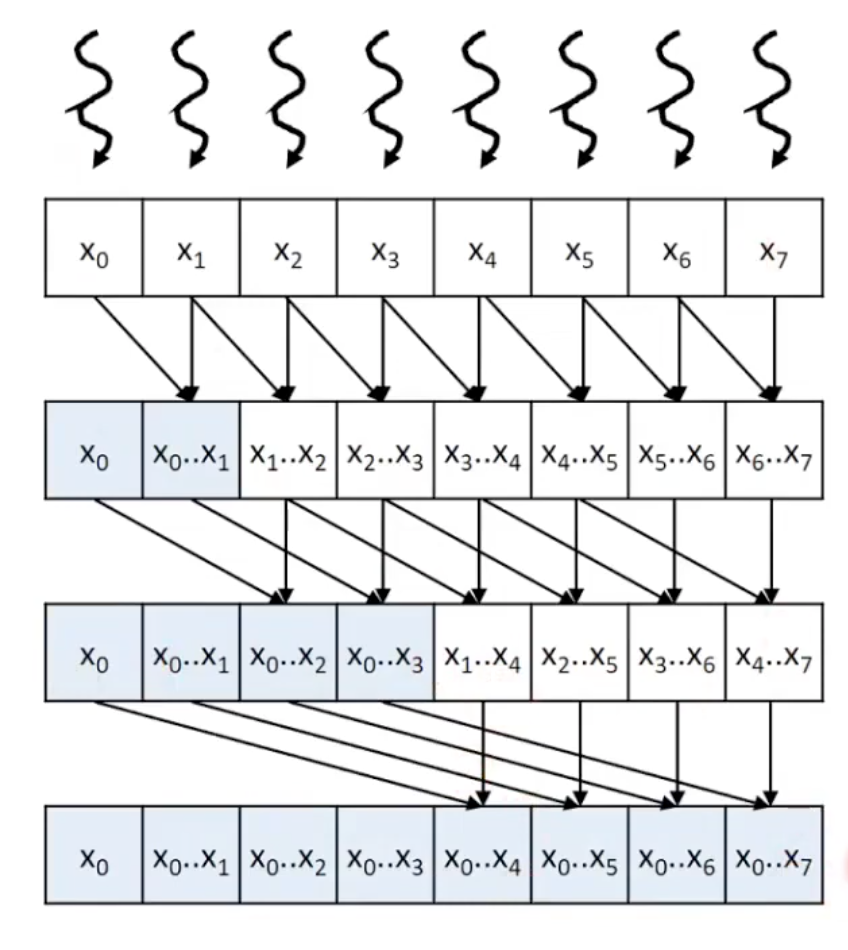
__global__ void scan_kernel(float* input, float* output, float* partialSums, int N) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
output[i] = input[i];
__syncthreads();
for (int stride = 1; stride <= BLOCK_DIM / 2; stride *= 2) {
float v;
if (threadIdx.x >= stride) {
v = output[i - stride];
}
__syncthreads(); // wait for everyone to read before updating
if (threadIdx.x >= stride) {
output[i] += v;
}
__syncthreads();
}
if (threadIdx.x == BLOCK_DIM - 1) {
partialSums[blockIdx.x] = output[i];
}
}
__global__ void add_kernel(float* output, float* partialSums, unsigned int N) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (blockIdx.x > 0) {
output[i] += partialSums[blockIdx.x - 1];
}
}
output[i] += output[i - stride];하면 안되는 이유- 다른 스레드가 동시에 같은 메모리 위치를 읽고 쓰는 상황이 발생함.
- 계속 같은 공간에서 global memory에 읽고 쓰는 방식이 적용됨.
- shared memory를 사용하여 성능 향상을 할 수 있음.
#define BLOCK_DIM 1024
__global__ void scan_kernel(float* input, float* output, float* partialSums, int N) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
__shared__ float buffer_s[BLOCK_DIM];
buffer_s[threadIdx.x] = input[i];
__syncthreads();
for (int stride = 1; stride <= BLOCK_DIM / 2; stride *= 2) {
float v;
if (threadIdx.x >= stride) {
v = buffer_s[threadIdx.x - stride];
}
__syncthreads(); // wait for everyone to read before updating
if (threadIdx.x >= stride) {
buffer_s[threadIdx.x] += v;
}
__syncthreads();
}
if (threadIdx.x == BLOCK_DIM - 1) {
partialSums[blockIdx.x] = buffer_s[threadIdx.x];
}
output[i] = buffer_s[threadIdx.x];
}
Double Buffering
- 동일한 버퍼를 입력과 출력에 모두 사용하기 때문에 동기화가 필요함.
- 입력과 출력에 다른 버퍼를 사용함으로써 해결할 수 있음.
- 두개의 버퍼를 사용하고 번갈아가면서 반복마다 출력과 입력의 역할을 바꿈.
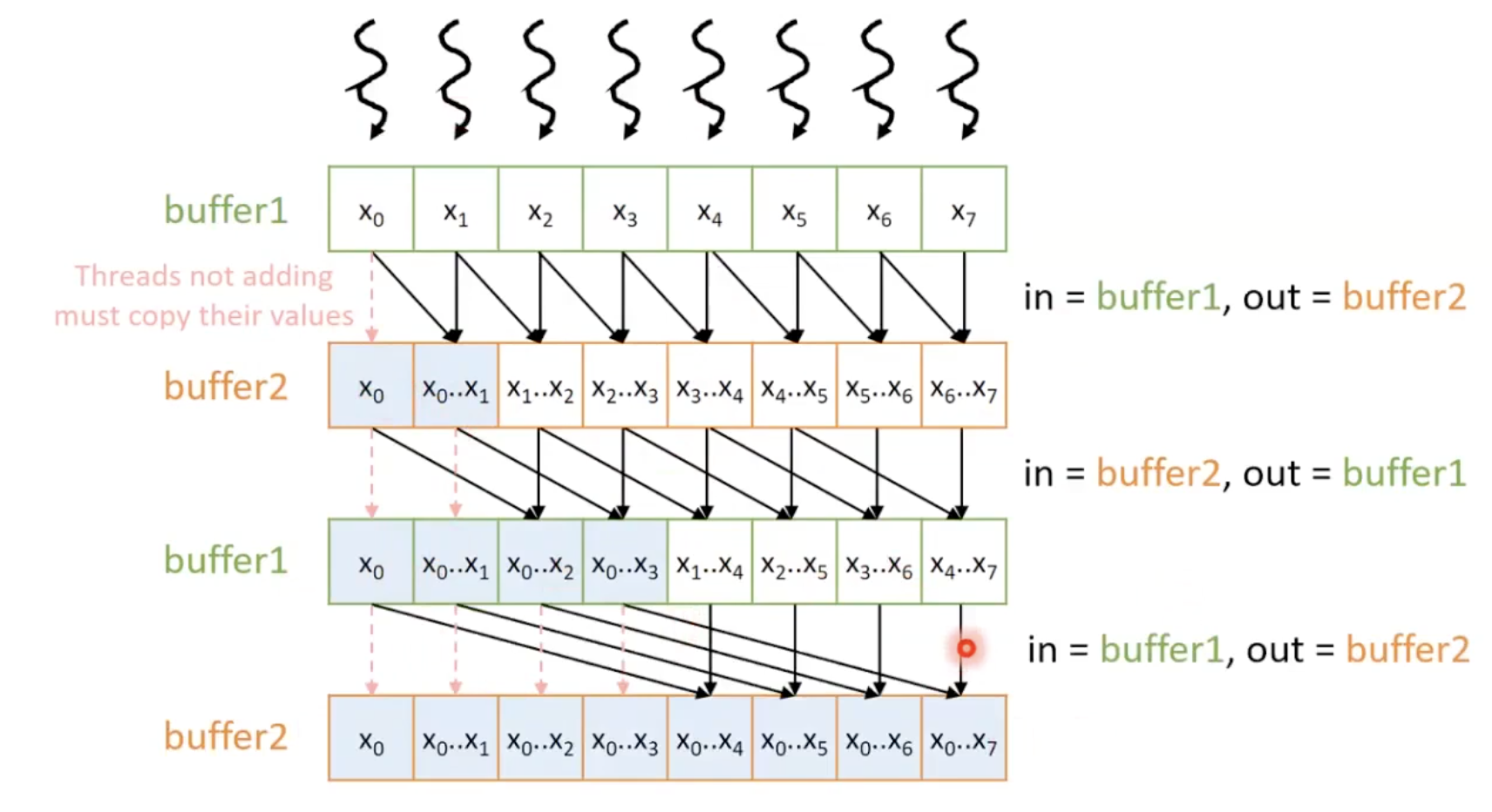
#define BLOCK_DIM 1024
__global__ void scan_kernel(float* input, float* output, float* partialSums, int N) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
__shared__ float buffer1_s[BLOCK_DIM];
__shared__ float buffer2_s[BLOCK_DIM];
float* inBuffer_s = buffer1_s;
float* outBuffer_s = buffer2_s;
inBuffer_s[threadIdx.x] = input[i];
__syncthreads();
for (int stride = 1; stride <= BLOCK_DIM / 2; stride *= 2) {
if (threadIdx.x >= stride) {
outBuffer_s[threadIdx.x] = inBuffer_s[threadIdx.x] + inBuffer_s[threadIdx.x - stride];
} else {
outBuffer_s[threadIdx.x] = inBuffer_s[threadIdx.x];
}
__syncthreads();
float* temp = inBuffer_s;
inBuffer_s = outBuffer_s;
outBuffer_s = temp;
}
if (threadIdx.x == BLOCK_DIM - 1) {
partialSums[blockIdx.x] = inBuffer_s[threadIdx.x];
}
output[i] = inBuffer_s[threadIdx.x];
}
Exclusive Scan
- inclusive scan처럼 만들 수 있음.
- 마지막 요소를 스킵하고 다른 요소들은 한칸씩 이동하여 로드함.
- 마지막 요소는 partial sum을 할때 fetch함.
#define BLOCK_DIM 1024
__global__ void scan_kernel(float* input, float* output, float* partialSums, int N) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
__shared__ float buffer1_s[BLOCK_DIM];
__shared__ float buffer2_s[BLOCK_DIM];
float* inBuffer_s = buffer1_s;
float* outBuffer_s = buffer2_s;
if (threadIdx.x == 0) {
inBuffer_s[0] = 0.0f;
} else {
inBuffer_s[threadIdx.x] = input[i - 1];
}
__syncthreads();
for (int stride = 1; stride <= BLOCK_DIM / 2; stride *= 2) {
if (threadIdx.x >= stride) {
outBuffer_s[threadIdx.x] = inBuffer_s[threadIdx.x] + inBuffer_s[threadIdx.x - stride];
} else {
outBuffer_s[threadIdx.x] = inBuffer_s[threadIdx.x];
}
__syncthreads();
float* temp = inBuffer_s;
inBuffer_s = outBuffer_s;
outBuffer_s = temp;
}
if (threadIdx.x == BLOCK_DIM - 1) {
partialSums[blockIdx.x] = inBuffer_s[threadIdx.x] + input[i];
}
output[i] = inBuffer_s[threadIdx.x];
}
__global__ void add_kernel(float* output, float* partialSums, unsigned int N) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (blockIdx.x > 0) {
output[i] += partialSums[blockIdx.x]; // changed!(removed -1)
}
}
작업 효율성 (Work efficiency)
- 병렬 알고리즘은 해당 순차 알고리즘과 동일한 양의 작업을 수행한다면 작업 효율적이라고 함.
- Scan 작업 효율성
- sequential scan : N 번 덧셈함
- Kogge-Stone parallel scan : log(n) step, N - 2^step 작업 per step
- total: (N -1) + (N -2) + ... + (N - N/2) = O(Nlog(N))
- 알고리즘이 work efficient 하지 않음.
- 더 많은 연산을 하더라도 더 적은 step에서 수행되기 때문에 빠를 수 있음.
- 리소스가 제한 된다면 병렬 알고리즘은 실제로 순차 알고리즘보다 더 많은 작업을 수행하기 때문에 느릴 수 있음.