pmpp lecture 12 Brent-Kung scan 요약
Source: Lecture 12 - Scan (Brent Kung)
Today
- Parallel patterns: scan
- Brent-Kung method
- Coarsening for scan
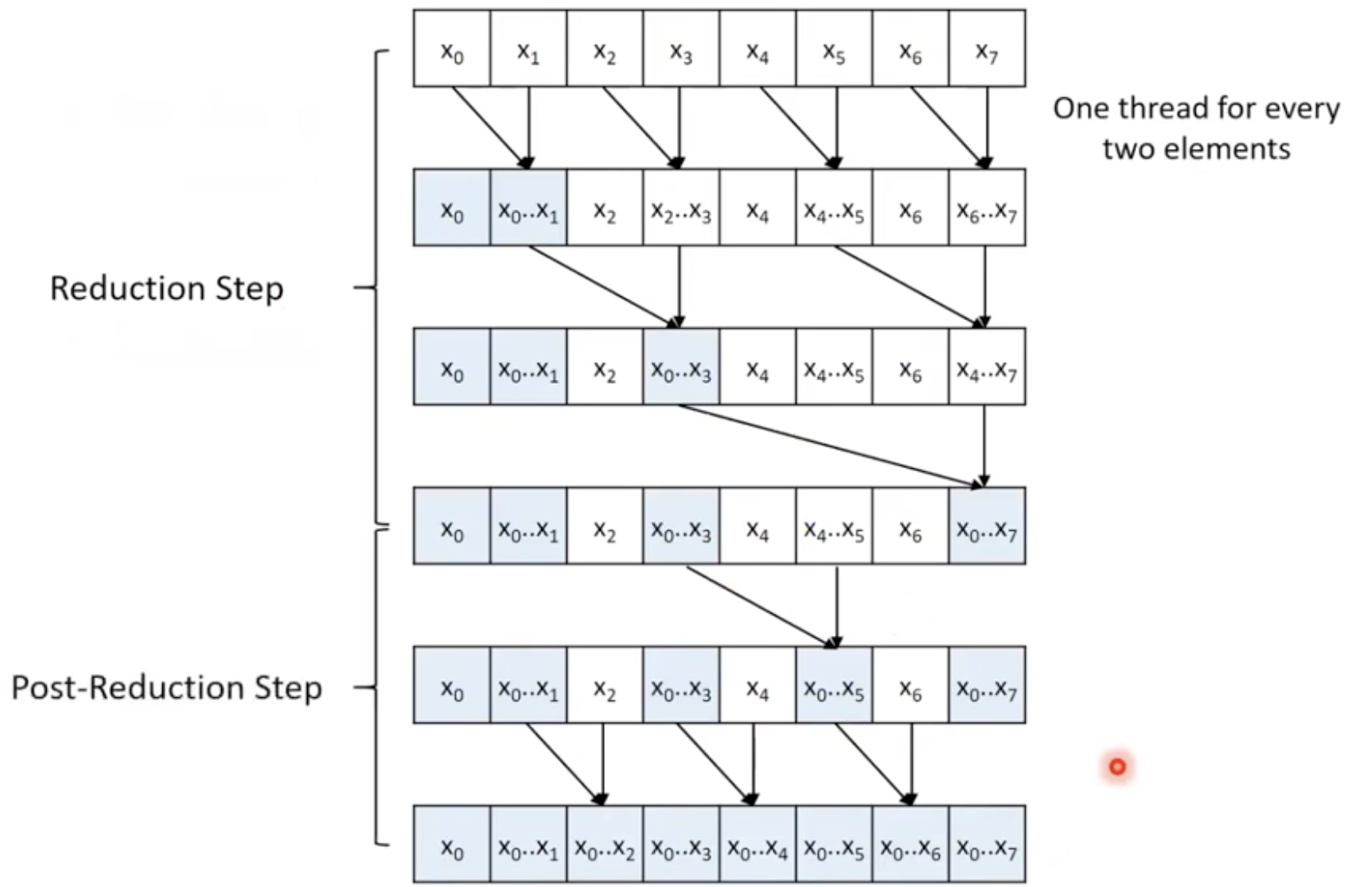
Brent-Kung Parallel Inclusive Scan
Kogge-Stone vs Brent-Kung
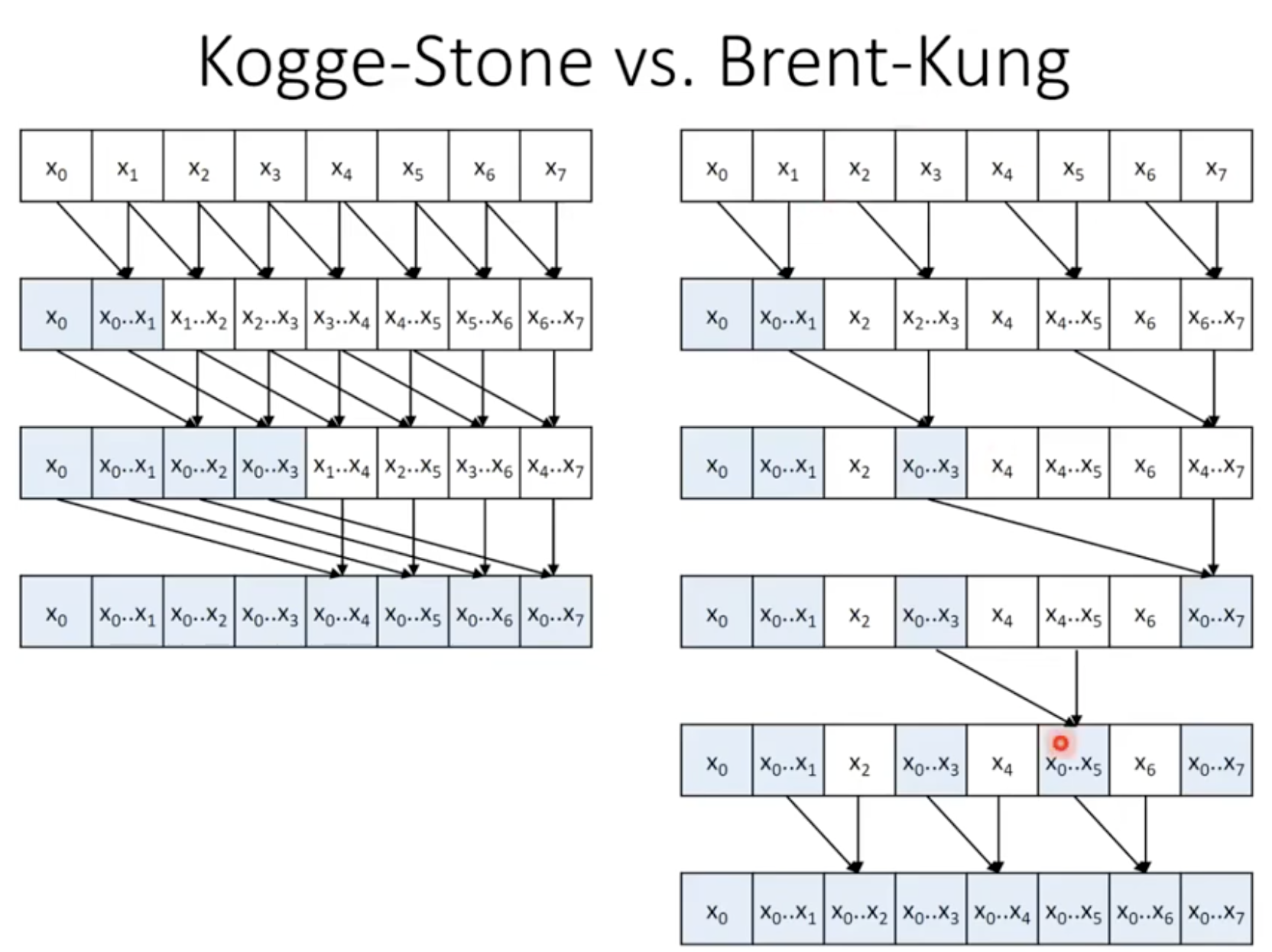
- 기본적으로 Brent-Kung이 덧셈이 더 적은 연산을 수행하고 총 연산수도 적지만 스텝이 더 많음
- Kogge-Stone Work Efficiency
- log(N) steps
- O(N * log(N)) operations
- Brent-Kung Work Efficiency
- Reduction Step
- log(N) steps
- 1 + 2 + 4 + ... + N/2 = N - 1 operations
- Post-Reduction step:
- log(N) - 1 steps
- (2-1) + (4-1) + ... + (N/2 -1) = (N - 2) - (log(N) - 1)
- Total
- 2 * log(N) - 1 steps
- O(N) operations
- Reduction Step
- Brent-Kung이 스텝 수는 더 많지만 더 작업 효율적이다.
Optimizations
- shared memory를 사용함.
- 전역 메모리 로드를 coalescing 할 수 있음.
- kogge-stone에서는 더블 버퍼링을 써야 했지만 brent-kung에서는 동일한 스레드에 쓰이는 경우가 없어서 그럴 필요 없음.
- contorl divergence를 최소화 해야함.
- kogge-stone에서는 스레드들이 서로 붙어있는애들이 함께 연산했기 때문에 control divergence 문제가 없었음.
- 활성 상태를 옆으로 유지하기 위해 매번 reindex를 할 예정임.
Re-index
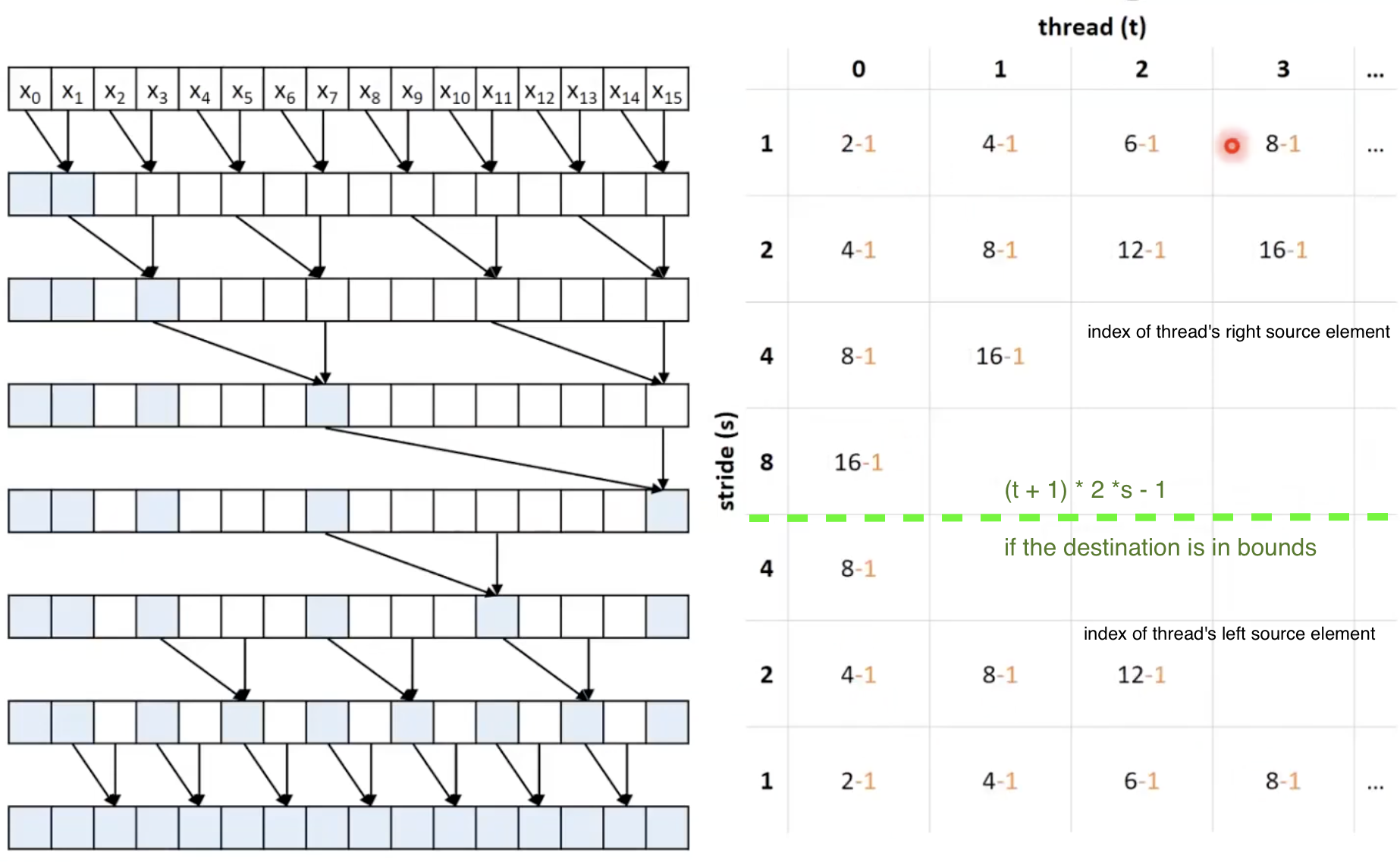
- stride를 loop index로 표기.
__global__ void scan_kernel(float* input, float* output, float* partialSums, int N) {
unsigned int segment = blockIdx.x * blockDim.x * 2; // 연산 스레드 하나당 두개의 값을 로드해놔야함.
__shared__ float buffer_s[2*BLOCK_DIM];
buffer_s[threadIdx.x] = input[segment + threadIdx.x];
buffer_s[threadIdx.x + BLOCK_DIM] = input[segment + threadIdx.x + BLOCK_DIM];
__syncthreads();
// Reduction step
for (unsigned int stride = 1; stride <= BLOCK_DIM; stride *= 2) {
unsigned int i = (threadIdx.x + 1) * 2 * stride - 1;
if (i < 2 * BLOCK_DIM) {
buffer_s[i] += buffer_s[i - stride];
}
__syncthreads();
}
// Post-reduction step
for (unsigned int stride = BLOCK_DIM / 2; stride > 0; stride /= 2) {
unsigned int i = (threadIdx.x + 1) * 2 * stride - 1;
if (i + stride < 2 * BLOCK_DIM) {
buffer_s[i + stride] += buffer_s[i];
}
__syncthreads();
}
if (threadIdx.x == 0) {
partialSums[blockIdx.x] = buffer_s[2 * BLOCK_DIM - 1]
}
output[segment + threadIdx.x] = buffer_s[threadIdx.x];
output[segment + threadIdx.x + BLOCK_DIM] = buffer_s[threadIdx.x + BLOCK_DIM];
}
Brent-Kung Exclusive Scan
- 첫번쨰 접근: Kogge-Stone때처럼 한칸씩 밀려서 input을 사용하면 됨.
- 두번째 접근: 다른 post-reduction 스텝을 사용.
- reduction step에서 x0...x7이 완성되면(마지막 단계) block의 partial sum으로 저장하고 0으로 대체함.
- 하지만 0은 마지막이 아니라 맨앞에 위치했어야 했음.
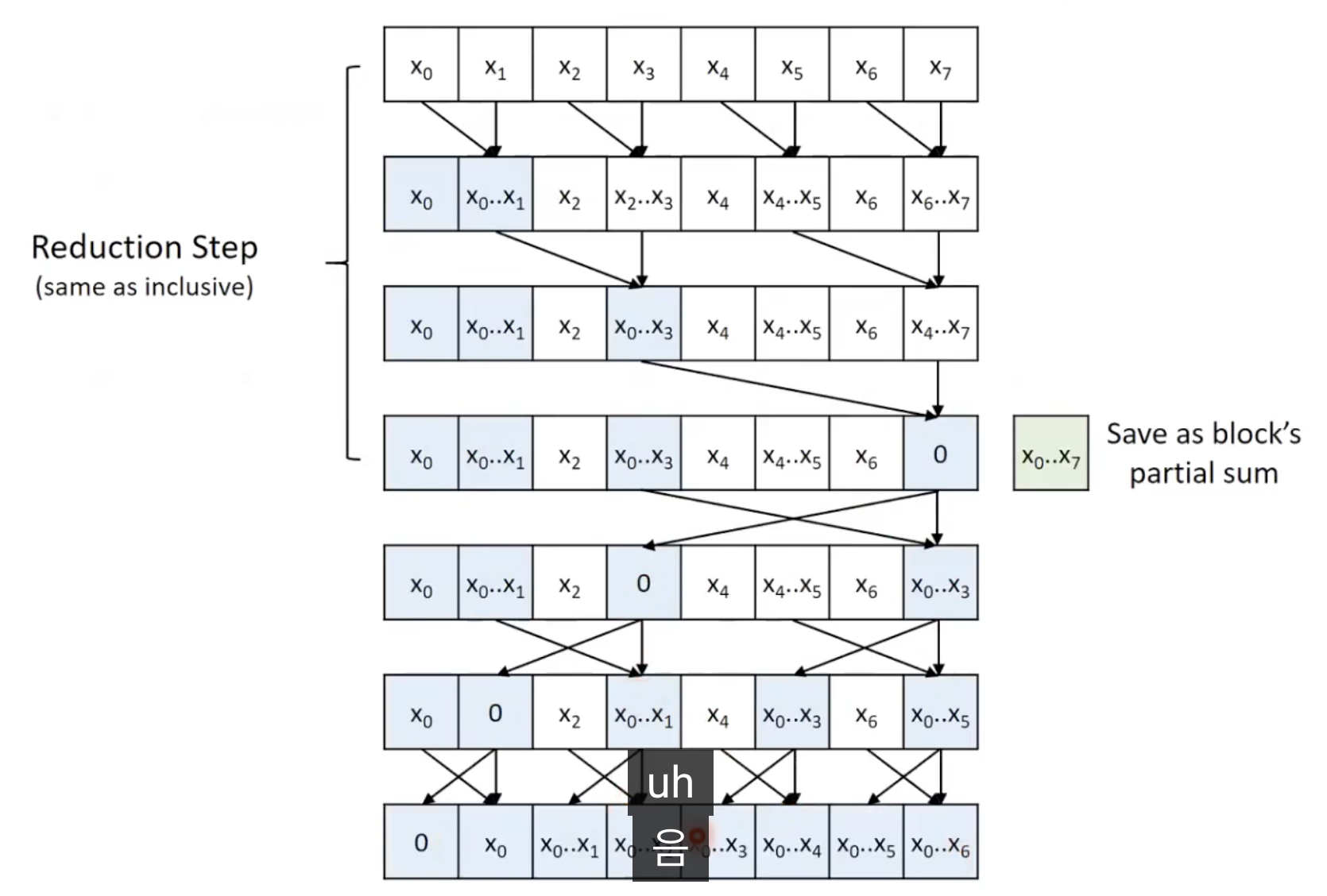
작업효율성(실제 발생하는일)
- Brent-Kung 방식이 Kogge-Stone 방식보다 이론적인 작업효율성은 더 높지만, 실제 비활성 스레드를 고려한 GPU의 실제 리소스 소비량은 O(N * log(N))임.
- GPU에서의 Brent-Kung이 Kogge-Stone 방식보다 퍼포먼스가 비슷하거나 나쁨.
- 여전히 흥미로운 연구 사례임.
Thread Coarsening In Parallel Scan
- 병렬 스캔은 여전히 작업효율성을 낮춤.
- 리소스가 비효율적이고 스레드가 직렬화하게 되면 오버헤드가 발생하는건 손해가 됨.
- 따라서 thread coarsening을 적용하여 각 스레드의 segment를 직렬화하면 좋음.
- 부분합에 대해서만 병렬 작업을 진행
#define BLOCK_DIM 1024
#define COARSE_FACTOR 8
__global__ void thread_coarsened_scan(float* input, float* output, float* partialSums, unsigned int N) {
unsigned int bSegment = BLOCK_DIM * COARSE_FACTOR * blockIdx.x;
__shared__ float buffer_s[BLOCK_DIM * COARSE_FACTOR];
for (unsigned int c = 0; c < COARSE_FACTOR; ++c) {
buffer_s[c * BLOCK_DIM + threadIdx.x] = input[bSegment + c * BLOCK_DIM + threadIdx.x];
}
__syncthreads();
// Thread scan
unsigned int tSegment = COARSE_FACTOR * threadIdx.x;
for (unsigned int c = 1; c < COARSE_FACTOR; ++c) {
buffer_s[tSegment + c] += buffer_s[tSegment + c - 1];
}
__shared__ float buffer1_s[BLOCK_DIM];
__shared__ float buffer2_s[BLOCK_DIM];
float* inBuffer_s = buffer1_s;
float* outBuffer_s = buffer2_s;
inBuffer_s[threadIdx.x] = buffer_s[tSegment + COARSE_FACTOR - 1];
__syncthreads();
for (int stride = 1; stride <= BLOCK_DIM / 2; stride *= 2) {
if (threadIdx.x >= stride) {
outBuffer_s[threadIdx.x] = inBuffer_s[threadIdx.x] + inBuffer_s[threadIdx.x - stride];
} else {
outBuffer_s[threadIdx.x] = inBuffer_s[threadIdx.x];
}
__syncthreads();
float* temp = inBuffer_s;
inBuffer_s = outBuffer_s;
outBuffer_s = temp;
}
if(threadIdx.x > 0) {
for (unsigned int c = 0; c < COARSE_FACTOR; ++c) {
buffer_s[tSegment + c] += inBuffer_s[threadIdx.x - 1];
}
}
if (threadIdx.x == BLOCK_DIM - 1) {
partialSums[blockIdx.x] = inBuffer_s[threadIdx.x];
}
__syncthreads();
for (unsigned int c = 0; c < COARSE_FACTOR; ++c) {
output[bSegment + c * BLOCK_DIM + threadIdx.x] = buffer_s[c * BLOCK_DIM + threadIdx.x];
}
}