pmpp lecture 14 merge 요약
Source: Lecture 14 - Merge
Merge
- 정렬된 병합(ordered merge)은 두 개의 정렬된 목록을 가져와서 하나의 정렬된 목록으로 결합하는 작업.
void mergeSequential(float* A, float* B, float* C, unsigned int m, unsigned int n) {
unsigned int i = 0; // A
unsigned int j = 0; // B
unsigned int k = 0; // C
while (i < m && j < n) {
if (A[i] < B[j]) {
C[k++] = A[i++];
} else {
C[k++] = B[j++];
}
}
while (i < m) {
C[k++] = A[i++];
}
while (j < n) {
C[k++] = B[j++];
}
}
// 매우 순차적인 직업같은데 어떻게 병렬화할 수 있을까?
Parallel Merge
- 많은 경우 입력과 출력은 직접적으로 일치함.
- 하지만 이 특정어플리케이션의 경우 출력을 분할하는 것이 나음.
- A: m | B: n | C: m + n
- 스레드 전체에 작업을 더 잘 분산시키고 싶다면 궁극적으로 모든 스레드가 동일한 요소의 수를 병합하는것.
- 스레드가 병합하는 요소의 수는 실제로 스레드가 쓸 요소의 수에 해당함.
- C배열을 가져와서 같은 크기의 세그먼트로 분할하고, 각 스레드는 한 세그먼트를 맡아 해당 세그먼트의 요소를 순차적으로 병합함.
Finding Input Segments
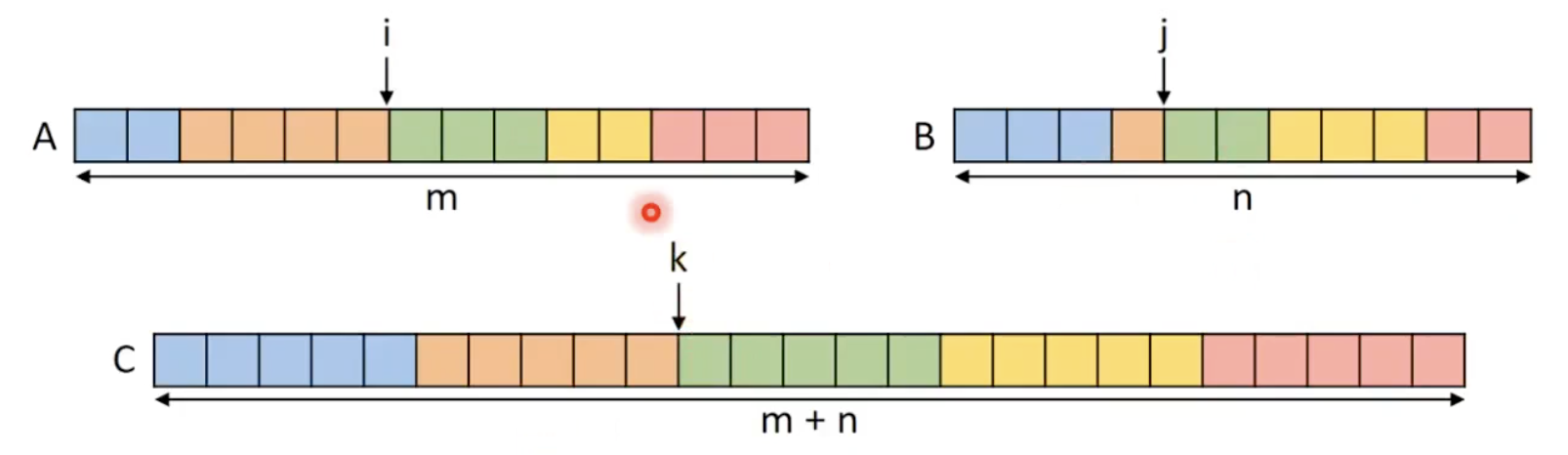
- 문제는 각 스레드가 병합할 A와 B의 해당요소를 어떻게 찾는가임.
- 각 스레드는 시작인덱스와 병합해야할 끝 인덱스를 A와 B에서 찾아야 함.
- k가 주어지고, i와 j를 찾는 문제임.
- i와 j를 k의 공동 순위로 지칭함.
k = i + j
- i와 j를 k의 공동 순위로 지칭함.
- k가 주어지고, i를 찾는 문제로 변경. j를 찾기 위해서는
j = k - i로 계산함.- i의 범위에 대해 생각해보자.
- 0 <= i <= m (배열의 끝에 도달했다면 m이 됨)
- 0 <= j <= n에서 k - n <= i <= k를 이끌어 낼 수 있음.
- max(0, k-n) <= i <= min(m, k)
- 전략: 범위 내에서 binary search를 수행
- A[i - 1] <= B[j] && B[j - 1] <= A[i] 여야함.
- 두가지 조건을 모두 충족하는 요소를 찾으면 우리가 찾았다는 뜻.
- i가 너무 높게 예측하면 첫번째 조건을 통과하지 못함.
- i가 너무 낮게 예측하면 두번째 조건을 통과하지 못함.
- i의 범위에 대해 생각해보자.
__device__ void mergeSequential(float* A, float* B, float* C, unsigned int m, unsigned int n) {
unsigned int i = 0; // A
unsigned int j = 0; // B
unsigned int k = 0; // C
while (i < m && j < n) {
if (A[i] < B[j]) {
C[k++] = A[i++];
} else {
C[k++] = B[j++];
}
}
while (i < m) {
C[k++] = A[i++];
}
while (j < n) {
C[k++] = B[j++];
}
}
__device__ unsigned int coRank(float* A, float* B, unsigned int m, unsigned int n, unsigned int k) {
// set bound
unsigned int iLow = (k > n) ? (k - n) : 0;
unsigned int iHigh = (k < m) ? k : m;
// binary search
while (true) {
unsigned int i = (iLow + iHigh) / 2;
unsigned int j = k - i;
if (i > 0 && j < n && A[i - 1] > B[j]) {
iHigh = i;
} else if (j > 0 && i < m && B[j - 1] > A[i]) {
iLow = i;
} else {
return i;
}
}
}
#define ELEM_PER_THREAD 6
#define THREADS_PER_BLOCK 128
#define ELEM_PER_BLOCK (ELEM_PER_THREAD * THREADS_PER_BLOCK)
// unsigned int numbBlocks = (m + n + ELEM_PER_BLOCK - 1) / ELEM_PER_BLOCK;
// merge_kernel <<< numBlocks, THREADS_PER_BLOCK >>> (A_d, B_d, C_d, m, n);
__global__ void merge_kernel(float* A, float* B, float* C, unsigned int m, unsigned int n) {
unsigned int k = (blockIdx.x * blockDimx.x + threadIdx.x) * ELEM_PER_THREAD;
if (k < m + n) {
unsigned int i = coRank(A, B, m, n, k);
unsigned int j = k - i;
unsigned int kNext = (k + ELEM_PER_THREAD < m + n) ? (k + ELEM_PER_THREAD) : (m + n);
unsigned int iNext = coRank(A, B, m, n, kNext);
unsigned int jNext = kNext - iNext;
mergeSequential(&A[i], &B[j], &C[k], iNext - i, jNext - j);
}
}
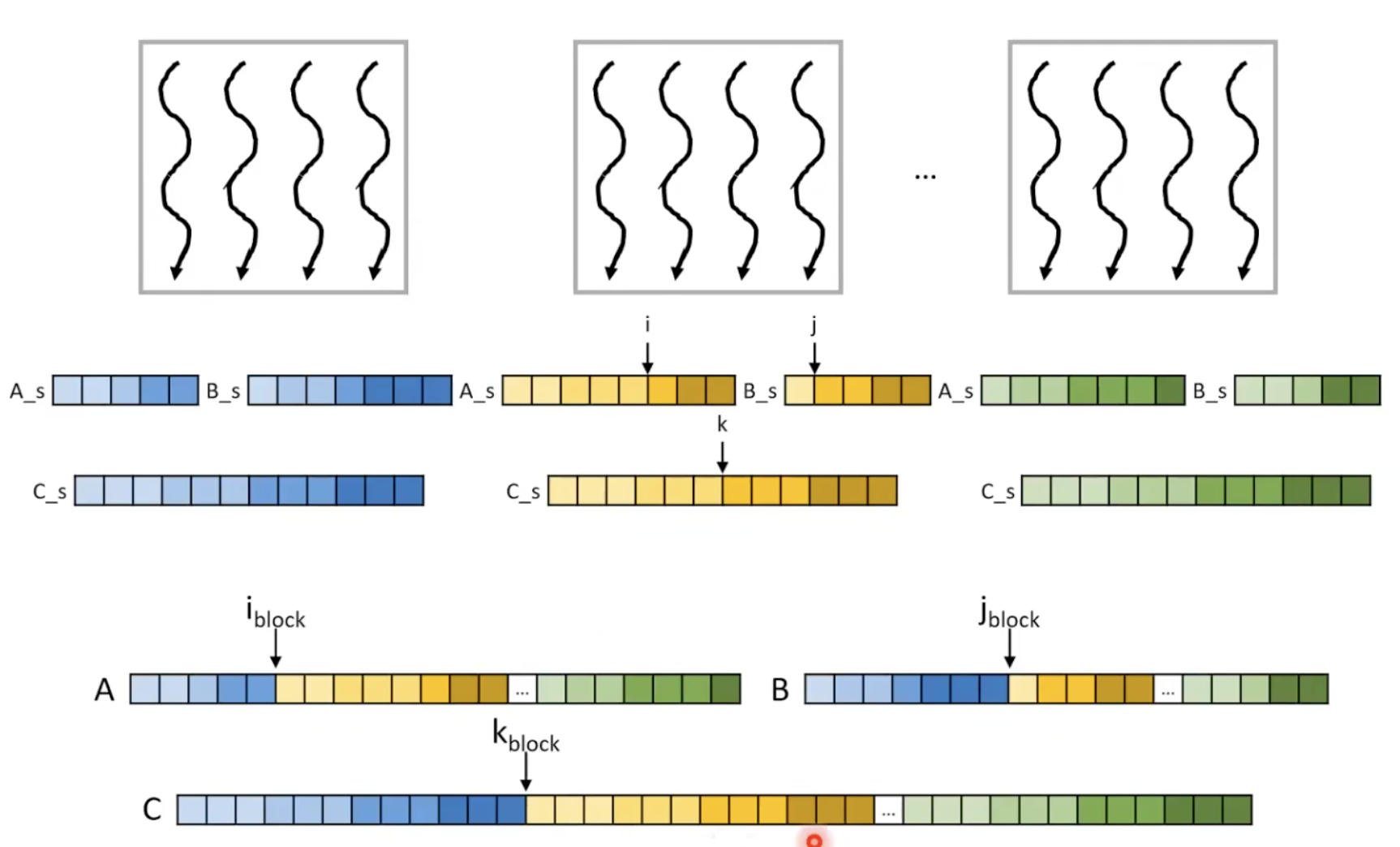
Shared Memory Tiling
- 매우 메모리 바운드 커널임.
- coalescing이 이루어지지 않음.
- corank 시에도 각 세그먼트들의 연속되지 않은 메모리에 접근하게 됨.
- 순차 병합 중에는 연속된 요소의 자체 세그먼트를 반복함. 따라서 쓰레드들이 연속적이지 않은 메모리에 접근하게 됨.
- 따라서 메모리 접근 패턴을 개선하기 위해 shared memory를 사용할 수 있음.
- 전체 블록의 세그먼트를 shared memory에 로드함.
- 그러면 global memory에서의 로드는 coalescing이 이루어짐.
- 블록의 스레드 중 하나만 블록의 input segment를 찾기위해 co-rank함수를 사용함.
- 그다음 스레드는 shared memory에서 input segment를 읽음.
- 각 스레드는 공유 메모리 내에서 co-rank를 수행하여 하위 세그먼트를 찾음
- 그런 다음 공유 메모리에서 병합을 수행하여 공유 메모리에 결과 배열을 제공
- 마지막으로 공유 메모리의 결과 배열을 global memory로 복사함.
- 전체 블록의 세그먼트를 shared memory에 로드함.
__global__ void merge_kernel(float* A, float* B, float* C, unsigned int m, unsigned int n) {
// Find the block's segments
unsigned int kBlock = blockIdx.x * ELEM_PER_BLOCK;
unsigned int kNextBlock = (blockIdx.x < gridDim.x - 1) ? (kBlock + ELEM_PER_BLOCK) : (m + n);
__shared__ unsigned int iBlock;
__shared__ unsigned int iNextBlock;
if (threadIdx.x == 0) {
iBlock = coRank(A, B, m, n, kBlock);
iNextBlock = coRank(A, B, m, n, kNextBlock);
}
__syncthreads();
unsigned int jBlock = kBlock - iBlock;
unsigned int jNextBlock = kNextBlock - iNextBlock;
// Load block's segments to shared memory
__shared__ float A_s[ELEM_PER_BLOCK];
unsigned int mBlock = iNextBlock - iBlock;
for (unsigned int i = threadIdx.x; i < mBlock; i += blockDim.x) {
A_s[i] = A[iBlock + i];
}
float* B_s = A_s + mBlock;
unsigned int nBlock = jNextBlock - jBlock;
for (unsigned int i = threadIdx.x; i < nBlock; i += blockDim.x) {
B_s[i] = B[jBlock + i];
}
__syncthreads();
// Merge in shared memory
__shared__ float C_s[ELEM_PER_BLOCK];
unsigned int k = threadIdx.x * ELEM_PER_THREAD;
if (k < mBlock + nBlock) {
unsigned int i = coRank(A_s, B_s, mBlock, nBlock, k);
unsigned int j = k - i;
unsigned int kNext = (k + ELEM_PER_THREAD < mBlock + nBlock) ? (k + ELEM_PER_THREAD) : (mBlock + nBlock);
unsigned int iNext = coRank(A_s, B_s, mBlock, nBlock, kNext);
unsigned int jNext = kNext - iNext;
mergeSequential(&A_s[i], &B_s[j], &C_s[k], iNext - i, jNext - j);
}
__syncthreads();
// Copy result to global memory
for (unsigned int k = threadIdx.x; k < mBlock + nBlock; k += blockDim.x) {
C[kBlock + k] = C_s[k];
}
}