pmpp lecture 16 sparse matrix computation (COO and CSR) 정리
Source: Lecture 16 - Sparse Matrix Computation (COO and CSR)
Today
- Parallel patterns: sparse matrix computation
- Case study: sparse matrix-vector multiplication (SpMV)
- Storage formats:
- COO (Coordinate Format)
- CSR (Compressed Sparse Row Format)
Sparse Matrices
- Dense matrix: 행렬의 대부분 요소가 0이 아닐 때 밀집 행렬이라고 함.
- Sparse matrix: 행렬의 대부분 요소가 0일 때 희소 행렬이라고 함
- 실제로 계산할 때 사용하는 행렬들의 대부분의 요소가 0 일 수 있음.
- 여러 가지를 절약하기 위해 이 0 인 성질 을 활용 할 수 있음
- 메모리(및 저장 공간) 절약: 0이 아닌 값만 저장.
- 메모리 대역폭 절약: 로드할 필요가 없다는 것을 뜻함.
- 계산 시간 절약: 0과 관련된 연산을 할 필요가 없음.
Sparse Matrix Storage Formats
- Coordinate Format (COO)
- Compressed Sparse Row Format (CSR)
- ELLPACK Format (ELL)
- Jagged Diagonal Format (JDS)
- ... many other formats
- 다른 형식을 사용하는 이유는 각각의 어플리케이션에 따라 효율성이 달라질 수 있기 때문
- 형식 디자인시 고려사항
- 공간 효율성(memory consumed)
- flexiblity(행렬을 추가, 재정렬하기 쉬운 정도)
- Accessibility(원하는 데이터를 얼마나 쉽게 찾을수 있는가)
- 메모리접근 패턴 (coalesced memory access)
- 로드 밸런스 (minimizing control divergence)
SpMV (희소 행렬-벡터 곱)
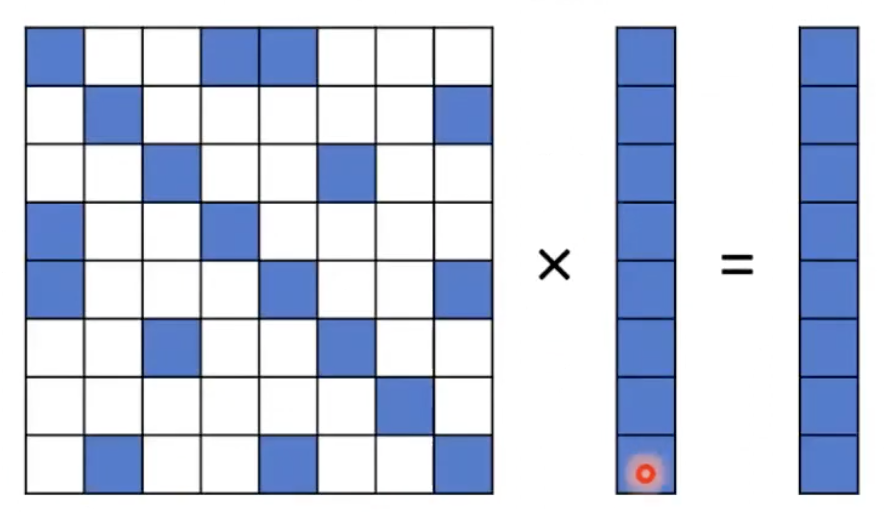
Coordinate Format (COO)
- 하얀 사각형은 0을 의미함.
- 모든 0이 아닌 값을 해당 행 인덱스와 열 인덱스와 함께 저장하는 것.
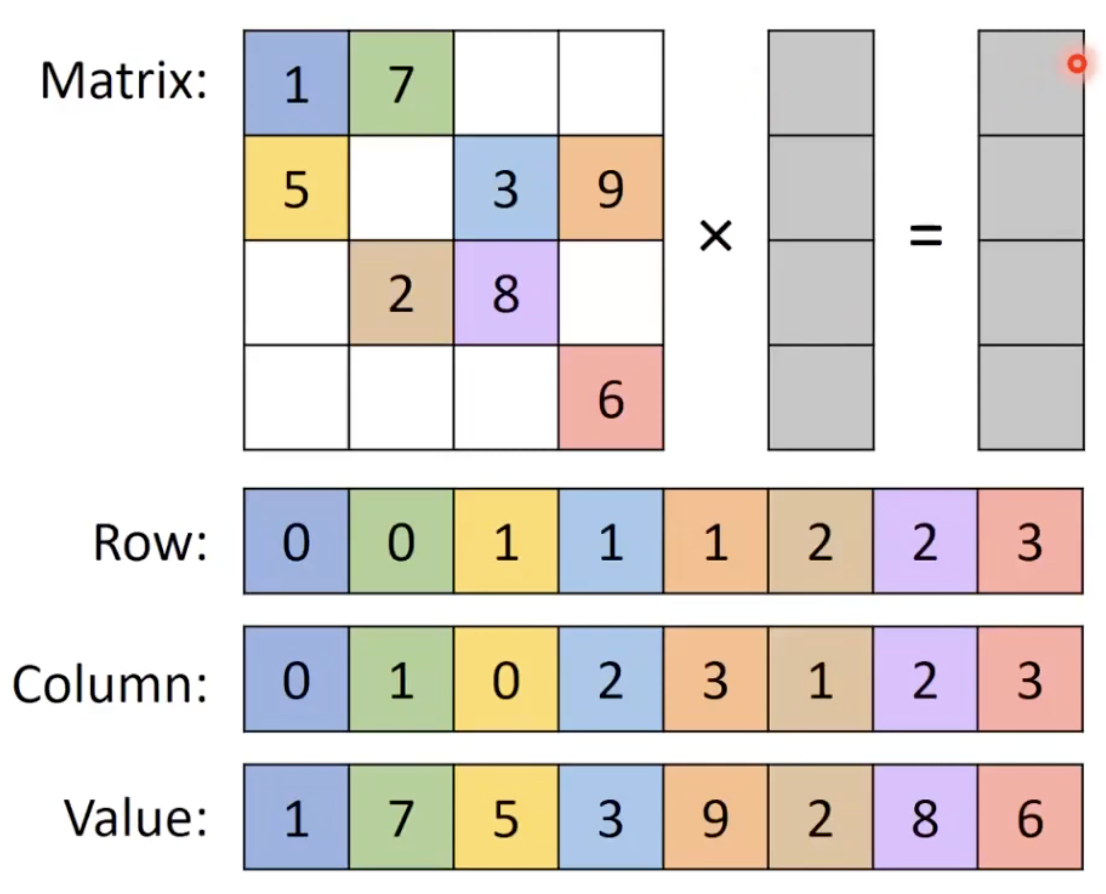
- 병렬화 하는 방법
- 모든 출력 값에 스레드를 할당 함.
- 행렬의 모든 0이 아닌 값에 스레드를 할당하고 해당 스레드가 해당 0이 아닌 값에 해당 하는 입력을 찾도록 함.
- COO format은 배열이 정렬되어야 하지 않음. 0이 아닌 값들은 어떤 순서로든 올 수 있음.
- 후자의 방법이 더 효율적임. (assign one thread per nonzero)
- 같은행에서 응답하는 스레드들이 같은 output에 쓰기를 시도함(원자적 연산이 필요함)
// unsigned int numThreadsPerBlock = 1024;
// unsigned int numBlocks = (cooMatrix_d.numNonzeros + numThreadsPerBlock - 1) / numThreadsPerBlock;
// spmv_coo_kernel <<< numBlocks, numThreadsPerBlock >>> (cooMatrix_d, inVector_d, outVector_d);
struct COOMatrix {
unsigned int numRows;
unsigned int numCols;
unsigned int numNonzeros;
unsigned int* rowIdxs;
unsigned int* colIdxs;
float* values;
}
__global__ void spmv_coo_kernel(COOMatrix cooMatrix, float* inVector, float* outVector) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < cooMatrix.numNonzeros) {
unsigned int row = cooMatrix.rowIdxs[i];
unsigned int col = cooMatrix.colIdxs[i];
float value = cooMatrix.values[i];
atomicAdd(&outVector[row], value * inVector[col]);
}
}
COO Tradeoffs
- 장점
- 요소 추가를 쉽게 해줌 (flexibility)
- 0이 아닌 요소가 주어지면 0이 아닌 요소의 행과 열을 쉽게 찾을 수 있음.
- 이는 0이 아닌 요소를 병렬화하기 쉽게 해줌.
- 접근이 좋고, coalescing 함.
- control divergence가 없음.
- 단점
- 한 행의 모든 요소를 찾기 힘듬.
- atomic operation을 사용해야 함.
Compressed Sparse Row (CSR)
- 같은 행에 있는 0이 아닌 값들을 서로 인접하게 저장함.
- 그리고 각 행의 첫번째 요소에 대한 인덱스만 저장함.
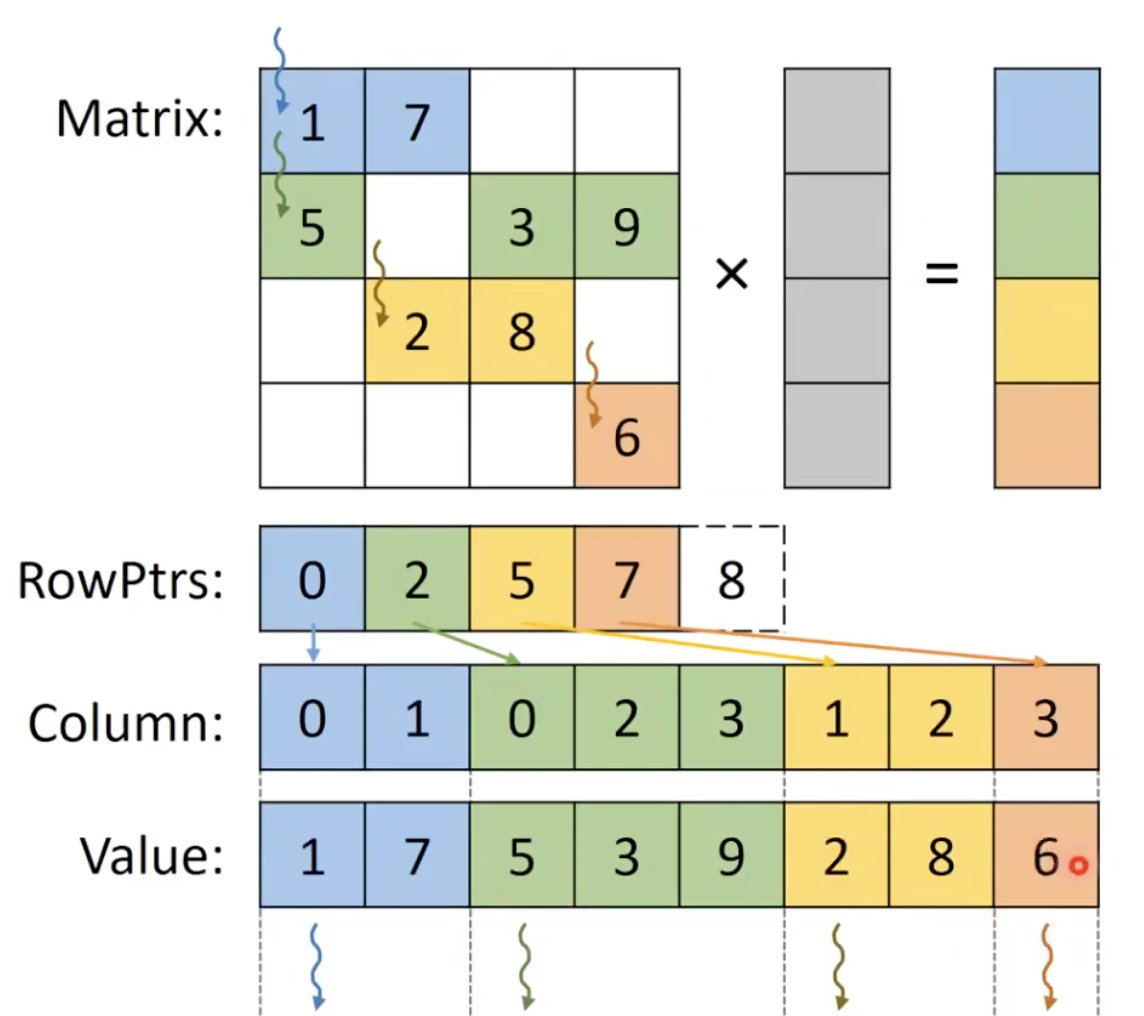
- 각 입력행을 반복하도록 스레드 하나를 할당하고 순차적으로 출력 요소를 업데이트함.
struct CSRMatrix {
unsigned int numRows;
unsigned int numCols;
unsigned int numNonzeros;
unsigned int* rowPtrs;
unsigned int* colIdxs;
float* values;
}
__global__ void spmv_csr_kernel(CSRMatrix csrMatrix, float* inVector, float* outVector) {
unsigned int row = blockIdx.x * blockDim.x + threadIdx.x;
if (row < csrMatrix.numRows) {
float acc = 0.0f;
for (unsigned int i = csrMatrix.rowPtrs[row]; i < csrMatrix.rowPtrs[row + 1]; i++) {
unsigned int col = csrMatrix.colIdxs[i];
float value = csrMatrix.values[i];
acc += value * inVector[col];
}
outVector[row] = acc;
}
}
CSR Tradeoffs (versus COO)
- 장점
- 공간 효율성이 나음: row pointer가 row indexes보다 작음
- 접근성 측면: 행이 주어지면, 각행에 대한 모든 non-zero 요소를 찾기 쉬움
- SpMV 연산에서 atomic 연산을 없애가 각 스레드가 각각의 출력을 담당함.
- 단점
- flexibility 측면: 요소 추가가 어려움.
- 접근성 측면: non-zero 요소가 주어지면 행을 알기 힘듬.
- 접근성 측면: 열이 주어져도 해당하는 non-zero 요소를 찾기 힘듬.
- spmv 연산에서 스레드들이 서로 다른 작업량을 가져서 control divergence 발생.
- spmv 연산에서 메모리가 coalsced하지 않음.
열버전인 CSC(Compressed Sparse Column)
- 열 기준으로 무언가 해야할 때 사용.