pmpp lecture 18,19 graph processing 정리
Source:
Representing Graphs
- 그래프를 논리적으로 표현하는 방법
- 인접행렬 (adjacency matrix)
- 보통 sparse 함.
- sparse matrices를 표현하는 포맷 중 하나를 사용할 수 있음.
- 일단 가중치가 없는 그래프에 집중함
- 모든 nonzero 값이 1이 될 것임.
- 무방향 그래프에 대해 집중함.
- 행렬이 대칭이 될 것임.(symmetric)
- 인접행렬 (adjacency matrix)
COO and CSR/CSC Representation
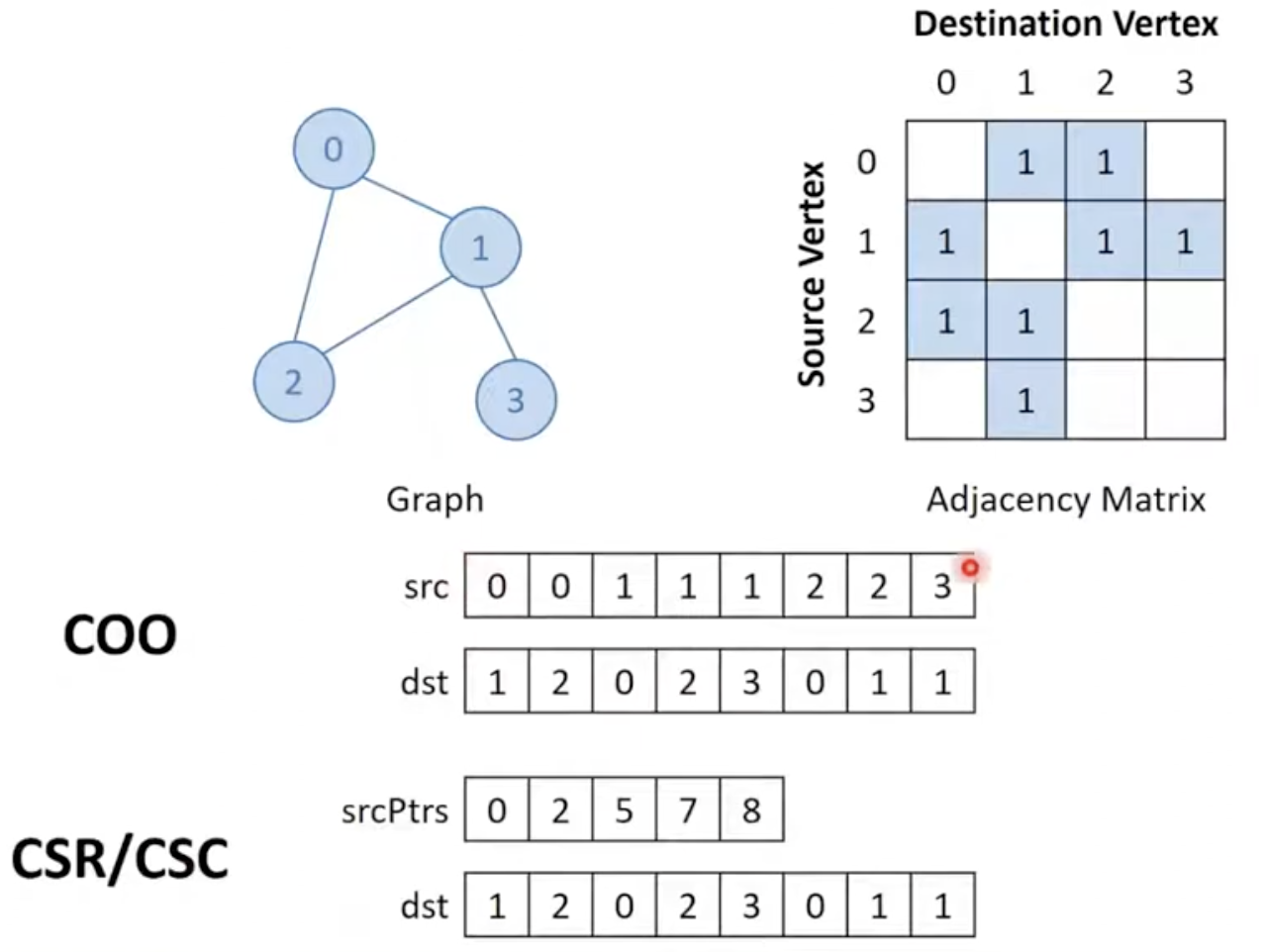
- value는 존재하면 항상 1이기때문에 따로 저장할 필요가 없음.
- symmetric이기 때문에 CSR과 CSC가 동일함.
- 그래프를 표현하기 위해 선택할 형식은 그래프를 병렬로 처리하는 방법에 대해 영향을 미침.
Approaches to Parallelizing Graph Processing
- 그래프 처리를 병렬화하는 두가지 주요 접근 방식이 있음.
- vertex-centric (정점 중심 접근 방식)
- 각 정점에 대해 스레드가 작업을 수행하도록 할당하는 것
- 스레드가 접한 모든 이웃들을 통과 시키려면 누가 제일 적합한가 -> CSR
- 일반적으로 CSR 또는 CSC를 사용함.
- 최적화를 생각하면 ELL 또는 JDS와 같은 다른 형식을 사용할 수도 있음.
- edge-centric (간선 중심 접근 방식)
- 각 엣지에 대해 스레드를 할당하여 작업을 수행함.
- 일반적으로 엣지의 소스와 destination을 살펴보는 것을 포함.
- 일반적으로 COO를 사용함.
- 0이 아닌 값을 주면 해당 값을 통해 row나 col을 찾는데 특화되어 있음.
- Hybrid
- 어떤 경우에는 CSR과 COO를 동시에 사용함.
- 예시) 간선이 주어지면, 그 간선에 대해 소스 정점의 이웃과 목적지 정점의 이웃을 찾음.
- 삼각형 count 등
Approaches to Breadth First Search (BFS)
- 목표: 어떤 소스 정점에서 각 정점의 거리 또는 레벨을 찾는 것.
- Vertex-Centric (두가지 버전이 있음)
- Top-down 방식(하향식 접근)
- 모든 정점에 대해서 해당 정점이 이전 레벨에 있었는지 확인하고, 방문하지 않은 모든 이웃들을 확인하고 현재 레벨로 표기함.
- 트리의 모든 정점의 부모에게 스레드를 할당하는 것과 같아서 하향식 접근이라 표현함.
- Bottom-up 방식(상향식 접근)
- 모든 정점에 대해 정점이 방문되지 않았는지 확인하고 이웃중에 하나라도 이전 레벨에 있다면 현재 레벨로 표기함.
- 스레드들이 잠재적으로 다음 레벨에 있는 정점들에서 작업하고 있어서 상향식 접근이라 표현함.
- Direction-optimized 방식 (방향 최적화)
- top-down으로 시작해서 bottom-up으로 전환함.
- 이전 레벨에 정점이 거의 없기 때문에 하향식 접근이 작업하는 스레드가 많지 않을 것임.
- 초기 반복에서는 방문한 정점이 거의 없기 때문에 상향식 접근 방식이 많은 작업을 수행할 것임.
- 따라서 초기 반복을 위해 하향식 접근을 사용하면 초기 반복이 빠르게 수행될 것임.
- top-down으로 시작해서 bottom-up으로 전환함.
- 시간 측정
- top-down: 12.85ms 🔴
- bottom-up: 2.882ms 🟡
- direction-optimized: 1.114ms 🚀
- Top-down 방식(하향식 접근)
- Edge-Centric
- 모든 엣지에 대해 스레드를 시작하고 엣지의 소스 정점이 이전 레벨에 있었는지 확인함. 그리고 해당 도착 정점이 마크되지 않았다면 현재 레벨에 마크함.
- Vertex-Centric과 다르게 COO 그래프를 사용함.
- 시간 측정: 1.684ms 🟢
- 상당히 잘 동작함을 알 수 있었음.
- 지금은 무방향 그래프라 엣지에 하나의 스레드가 배치되었지만 실제로는 두개를 할당해야 할 수도 있음.
Dataset Implications
- 그래프의 구조에 따라 최적의 병렬 접근 방식이 달라짐.
- 고차수(high-degree) 그래프에서는 vertex-centric bottom-up방식과 edge-centric 접근 방식이 더 효과적임.
- 소셜 네트워크 그래프 같은곳
- 부하 불균형을 더 잘 처리하기 때문에 그러함
- vertex-centric top-down 방식은 낮은 차수의 그래프에서 더 잘 동작함.
- 실생활에서는 지도가 낮은 차수의 그래프일 가능성이 높음.(road graph)
- roadNet 측정 결과
- edge-centric: 234ms
- direction-optimized: 228.09ms
- bottom-up: 204.614ms
- top-down: 66.425ms 🚀
- 이전 반복에서 방문한 정점에 대해서만 작업을 수행하기 때문. 각 반복마다 방문하는 정점의 수가 적은편이기 때문에 더 많은 반복과 반복당 더 적은 정점을 갖게 됨.
- 높은 차수의 정점을 만날때마다 이웃을 처리하기위해 더 많은 스레드를 할당하는 식으로 최적화할 수 있음.
Similarity Between BFS and SpMV
- SpMV에서 했던것은 모든 행에 대해서 nonzero 요소를 순차적으로 접근하는 것과 같음.
- BFS에서 bottom-up approach를 보면 모든 정점에 대해 모든 엣지에 대해서 순차적으로 접근함.
- 이 두개가 사실상 같은 행동임.
- 마찬가지로 BFS의 top-down approach처럼 SpMV를 수행하는 방법도 있다고 함.
Linear Algebraic Formulation of Graph Problem (그래프 문제의 선형 대수적 공식화)
- 약간의 수정으로, BFS를 SpMV와 정확히 동일하게 공식화할 수 있음.
- 우리가 해야할 일은 방문 목록을 입력 벡터 및 출력 벡터로 사용하는 것
- 우리가 원하는 것을 얻기 위해서 약간의 다른 vector 연산을 수행했던 것임.
- 하지만 일반적으로 SpMV가 dominant computation으로 남을 것.
- 사실 많은 그래프 문제는 희소 선형 대수 계산으로 공식화 될 수 있음.
- BFS를 SpMV로 공식화하면 얻는 장점은?
- 최적화된 라이브러리를 활용하여 고성능 선형 대수학을 수행할 수 있음.
- 선형 대수 연산은 매우 좋고 쉽게 병렬화 되는 경향이 있음.
- 단점은
- 그래프 문제를 해결하는데 항상 가장 효율적인 방식은 아닐 것이라는 것임.
- BFS를 SpMV로 공식화하면 얻는 장점은?
symmetric vs not symmetric graph
- symmetric 그래프라면 들어오는 엣지와 나가는 엣지가 동일하므로, top-down이나 bottom-up이나 같은 형식을 사용해도 괜찮음
- symmetric 그래프가 아니라면 들어오는 엣지와 나가는 엣지가 다름.
- 하향식 접근 방식은 도달할 수 있는 이웃을 보기 위해 자신으로부터 이웃으로 가는 모든 엣지가 필요함.
- CSR 표현에 해당함
- 상향식 접근 방식은 우리를 도달할 수 있는 모든 이웃을 보기 위해 들어오는 엣지를 확인해야 함.
- CSC 표현에 해당함
- hybrid 방식을 도입하려면 두 표현 모두 필요한 상태임.
- 하향식 접근 방식은 도달할 수 있는 이웃을 보기 위해 자신으로부터 이웃으로 가는 모든 엣지가 필요함.
Redundant Work (중복 작업)
- 우리가 얘기했던 병렬 접근방식에서 매 반복 마다 모든 정점 또는 모서리를 확인해야 했음.
- 구현하기 쉬움, 매우 병렬적임, 스레드간에 동기화를 신경쓸 필요가 없음(완전히 독립적으로 작동하기 떄문에)
- 불필요한 작업을 너무 많이 함.
- 많은 스레드가 자신이 이번 작업에 필요하지 않다는 것을 확인해야 하기 때문에
Reducing Redundancy
- 목표: 이전 레벨에 속한 정점(vertex)만 확인하는 것
- 방법: 해당 레벨에서 방문한 정점들을 큐에 넣고, 해당 큐에 있는 정점들 만 처리함
- 정점들은 각 레벨에서 큐에 추가되고 이 정점들이 레벨의 프론티어(frontier)를 형성함.
- 단점: 공유 뷰에 정점을 추가하기 위해 동기화가 필요함.
__global__ void bfs_kernel(CSRGraph, csrGraph, unsigned int* level, unsigned int* prevFrontier, unsigned int* currFrontier, unsigned int numPrevFrontier, unsigned int* numCurrFrontier, unsigned int currLevel) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < numPrevFrontier) {
unsigned int vertex = prevFrontier[i];
for (unsigned int edge = csrGraph.srcPtrs[vertex]; edge < csrGraph.srcPtrs[vertex + 1]; edge++) {
unsigned int neighbor = csrGraph.dst[edge];
if (atomicCAS(&level[neighbor], UINT_MAX, currLevel) == UINT_MAX) { // 다른 스레드에서 동일한 정점에 대해 방문했을 경우
unsigned int currFrontierIdx = atomicAdd(numCurrFrontier, 1);
currFrontier[currFrontierIdx] = neighbor;
}
}
}
}
atomicCAS(address, compare, val)*address == compare이면 →*address = val로 변경- 리턴:
*address의 원래 값 (변경 전 값)
Queue Privatization
- 모든 스레드가 동일한 전역 카운터를 원자적으로 증가시켜 요소를 큐에 삽입하고 있음
- global 메모리 접근과 높은 의도성으로 인한 serialization으로 latency가 높음
- privatizaiton
- 각 스레드 블록이 개인 큐를 유지하고 완료시 전역 뷰에 항목을 커밋함.
- 순서가 변경되도 상관없기 때문에 scan이 필요하지 않음.
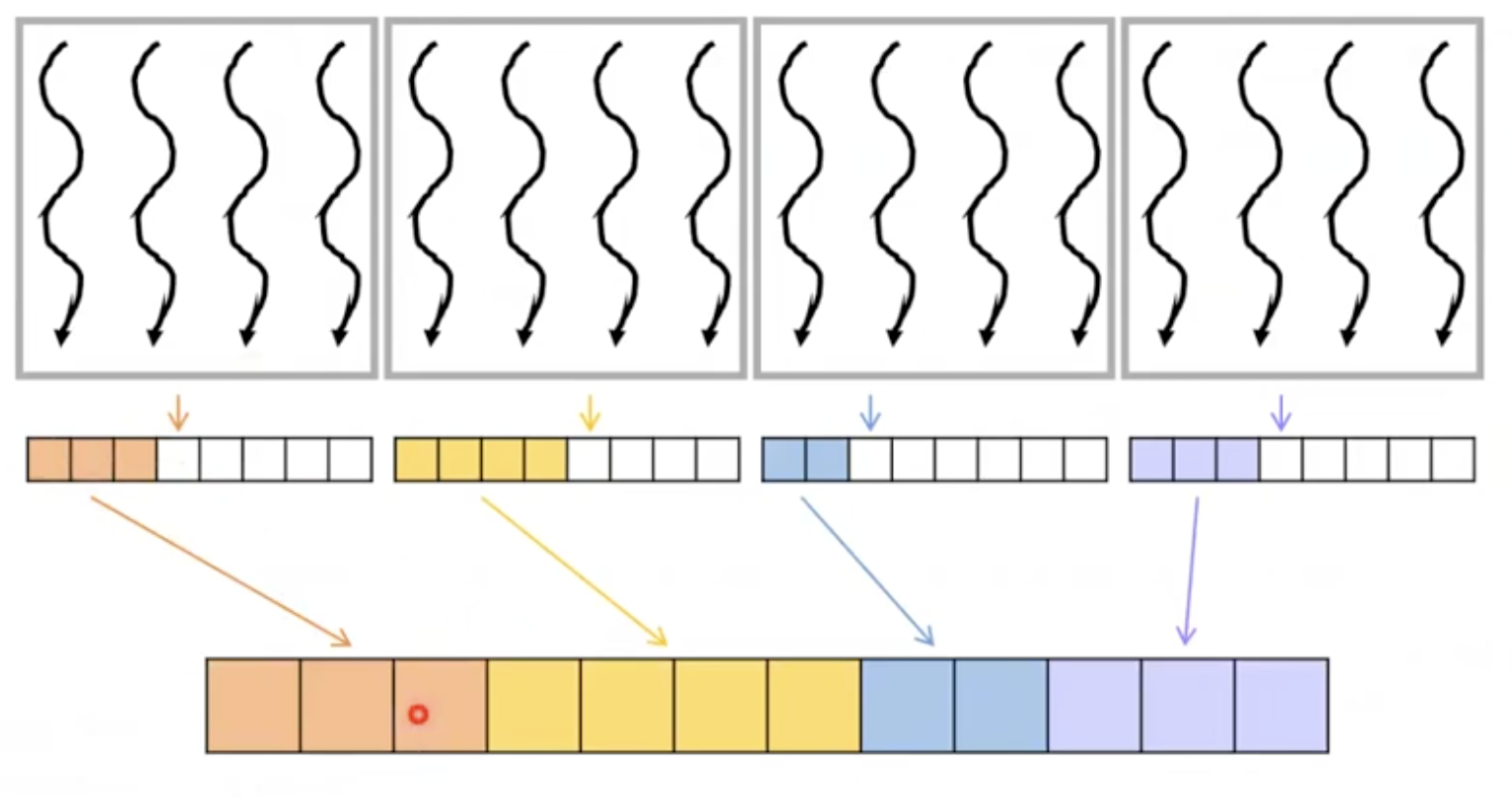
#define LOCAL_QUEUE_SIZE 2048
__global__ void bfs_kernel(CSRGraph, csrGraph, unsigned int* level, unsigned int* prevFrontier, unsigned int* currFrontier, unsigned int numPrevFrontier, unsigned int* numCurrFrontier, unsigned int currLevel) {
__shared__ unsigned int currFrontier_s[LOCAL_QUEUE_SIZE];
__shared__ unsigned int numCurrFrontier_s;
if (threadIdx.x == 0) {
numCurrFrontier_s = 0;
}
__syncthreads();
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < numPrevFrontier) {
unsigned int vertex = prevFrontier[i];
for (unsigned int edge = csrGraph.srcPtrs[vertex]; edge < csrGraph.srcPtrs[vertex + 1]; edge++) {
unsigned int neighbor = csrGraph.dst[edge];
if (atomicCAS(&level[neighbor], UINT_MAX, currLevel) == UINT_MAX) { // 다른 스레드에서 동일한 정점에 대해 방문했을 경우
unsigned int currFrontierIdx_s = atomicAdd(numCurrFrontier_s, 1);
if (currFrontierIdx_s < LOCAL_QUEUE_SIZE) {
currFrontier_s[currFrontierIdx_s] = neighbor;
} else {
// 오버 플로가 발생하면 그냥 global에 직접 넣는다.
numCurrFrontier_s = LOCAL_QUEUE_SIZE;
unsigned int currFrontierIdx = atomicAdd(numCurrFrontier, 1);
currFrontier[currFrontierIdx] = neighbor;
}
}
}
}
__syncthreads();
__shared__ unsigned int currFrontierStartIdx;
if (threadIdx.x == 0) {
currFrontierStartIdx = atomicAdd(numCurrFrontier, numCurrFrontier_s);
}
__syncthreads();
for (unsigned int currFrontierIdx_s = threadIdx.x; currFrontierIdx_s < numCurrFrontier_s; currFrontierIdx_s += blockDim.x) {
currFrontier[currFrontierStartIdx + currFrontierIdx_s] = currFrontier_s[currFrontierIdx_s];
}
}
// 14.826ms -> 14.676ms로 거의 변화 없음.
// 하드웨어나 그래프에 따라 달라질 수 있음.
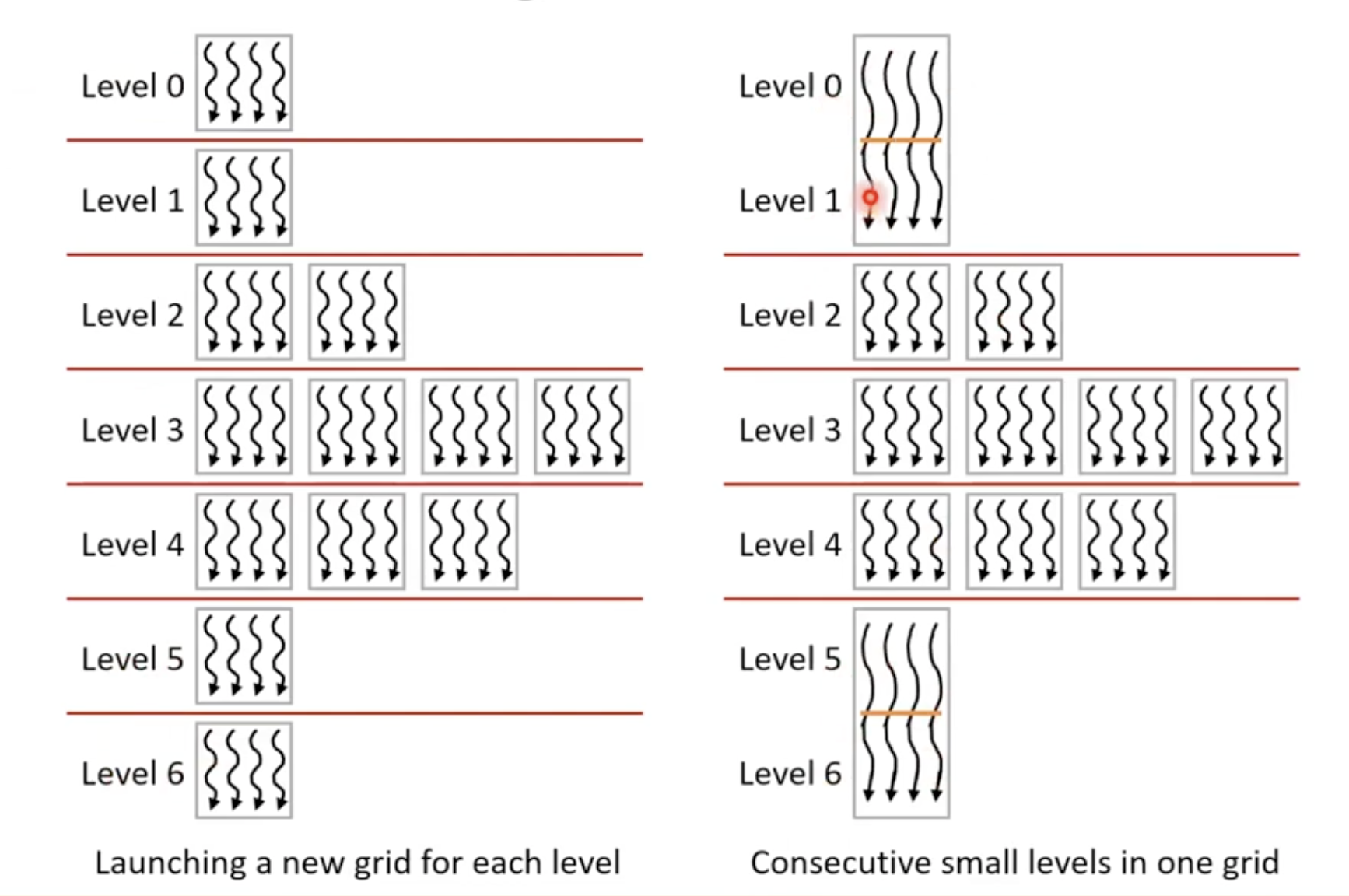
Minimizing Launch Overhead
- 원래는 전체 정점에 대해 스레드를 생성했었지만 이제 프론티어에 있는 정점의 수 만큼만 스레드를 생성하면 됨.
- 최적화의 기회를 제공함
- 레벨 간에 동기화가 필요함.
- 다음 레벨로 진행하기 전에 모든 스레드가 현재 레벨의 모든 정점을 큐에 넣을 때까지 기다려야 하기 때문에
- 지금까지 레벨간 동기화를 위해 해왔던 것은 각 레벨마다 새로운 그리드를 시작하는 것이였음.
- 새로운 그리드를 시작하는 오버헤드와 카운터를 복사하기 위한 오버헤드가 발생함.
- 최적화: 연속된 레벨에 충분히 적은 수의 정점이 있다면 이 정점들이 하나의 스레드 블록에 의해 실행될 수 있도록 함
- 그러면 우리는 단일 스레드 블록에서 여러 레벨을 실행할 수 있음. 그리고
__syncthreads를 사용하여 동기화할 수 있음. - 우리가 해야 할 그리드 실행의 총 횟수를 줄여줌.
- 그러면 우리는 단일 스레드 블록에서 여러 레벨을 실행할 수 있음. 그리고
- 14.13ms로 실행시간 단축됨.
- 현재 레벨의 정점 수를 확인하고, 현재 레벨의 정점 수가 단일 스레드 잠금으로 처리할 수 있는 정점수보다 적고 다음 큐를 가지고 있고, 역시 단일 스레드에서 처리할 수 있는 정점수보다 적으면, 이경우 스레드를 동기화하고 한번에 처리할 수 있음.