pmpp lecture 21 pinned memory and streams 정리
Source: Lecture 21 - Pinned Memory and Streams
Today
cudaMemcpy복사 시간으로 인해 성능이 떨어짐.- 어떻게 이 시간을 줄일 수 있을지.
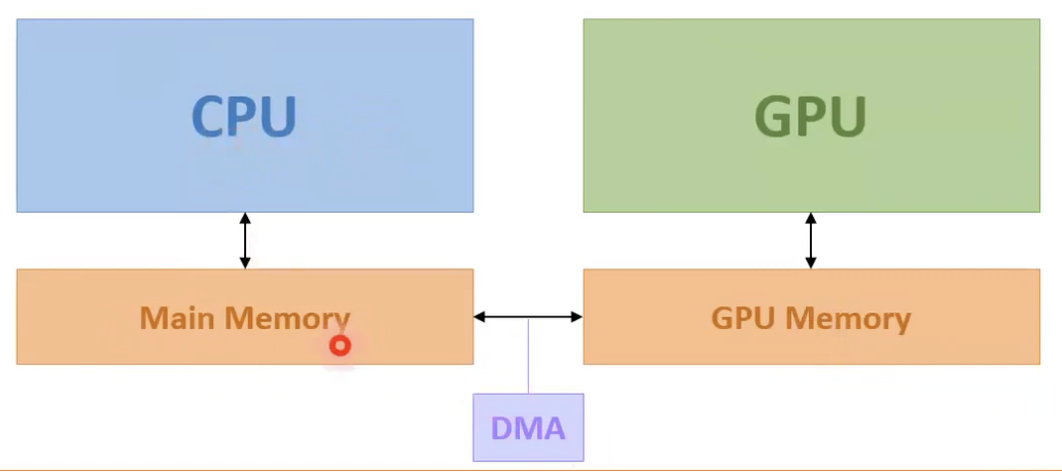
Direct Memory Access
- 하드웨어 내의 일부 하드웨어 장치가 CPU 개입없이 메인 메모리에 접근할 수 있도록 하는 아이디어
- CPU와 GPU간의 복사는 DMA를 사용함.
- CPU의 메인 메모리에서 GPU 메모리로 전송하는 DMA엔진은 GPU측에 있음. 하지만 CPU 측에서 GPU 드라이버를 개입시켜야 함.
- 이점: CPU가 메모리 복사를 진행하는 동안 다른 일을 할 수 있음.
- 단점:
- CPU는 virtual address로 작동, DMA엔진은 주소변환 기능을 갖고 있지 않음.
- physical address를 읽을 때의 문제점: 메모리가 swapped out 되면 이를 감지할 방법이 없음.
Pinned Memory
- DMA는 메모리에 접근할때 physical address를 사용함.
- OS가 같은 physical address 상에서 다른 가상 페이지로 현재 가상페이지를 교체할 때 감지할 수 없음.
- 데이터 손상을 피하기 위해, 운영체제는 DMA에 의해 접근되는 페이지를 스왑할 수 없어야 함.
- DMA에 의해 접근되는 페이지들은 페이지 잠금 상태여야 하며 다른 말로하면 고정되어야 함.(pinned or page-locked)
- 이 페이지들은 마크 되어서 OS가 스왑할 수 없게 함.
cudaMemcpy의 동작
- Host to device
- CPU는 고정 메모리 버퍼에 데이터를 복사함.
- DMA는 고정 메모리 버퍼에서 데이터를 가져와 GPU 메모리로 전송함.
- Device to host
- DMA는 GPU 메모리에서 데이터를 가져와 고정 메모리 버퍼로 전송함.
- CPU는 고정 메모리 버퍼에서 데이터를 복사함.
cudaMemcpy는 실제로 두번의 복사를 수행하며, 이는 오버헤드를 일으킴.
Faster Copies
- 호스트 배열을 고정 메모리에 직접 할당하여 복사 속도를 높일 수 있음.
- CUDA는 고정 메모리에 호스트 데이터를 할당하거나 해제할 수 있도록 API를 제공함.
cudaError_t cudaMallocHost(void **devPtr, size_t size);cudaError_t cudaFreeHost(void *devPtr);
- 모든것을 고정 메모리에 할당하면 사용 가능한 가상 페이지를 줄이기 때문에 운영체제가 스와핑할 옵션을 잃는 셈이기 때문에 성능 저하를 유발할 수 있음.
- 핀 메모리는 GPU와 CPU를 오가며 자주 복사하는 데이터에만 사용해야 함.
- GPU는 당연히 성능이득을 얻게 되고 CPU 연산도 더이상 page fault가 발생하지 않을것이므로 함께 효과를 봄.
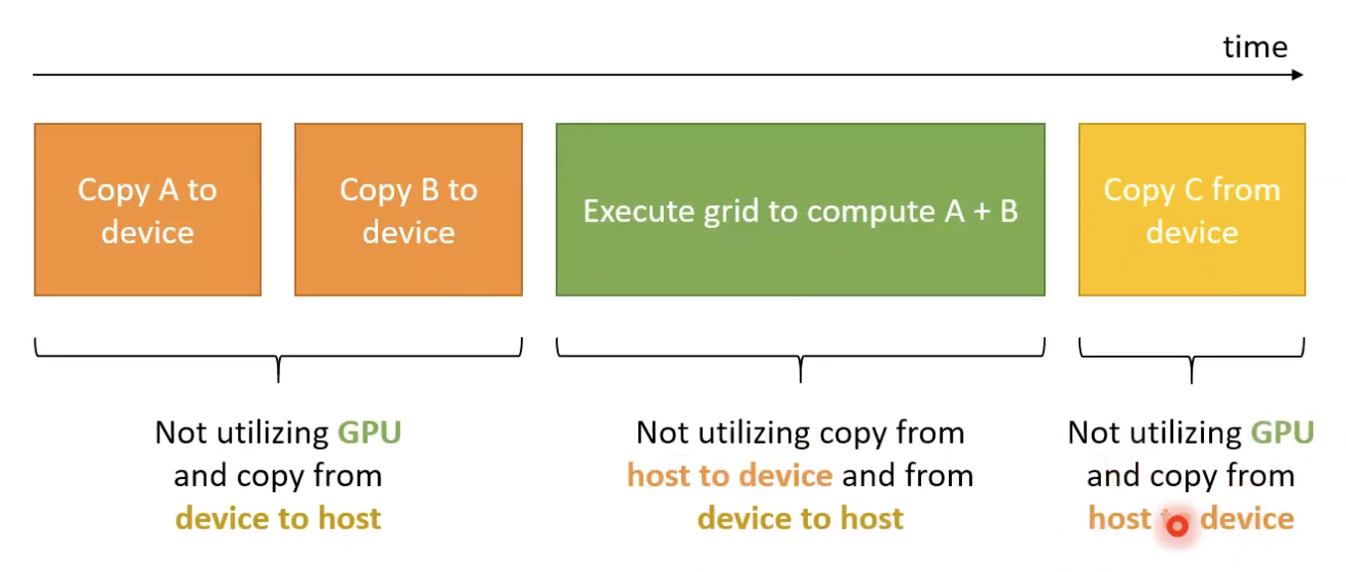
시스템 아키텍쳐 수준의 병렬성
- GPU에서 그리드를 실행하고
- 호스트에서 디바이스로 복사하고
- 디바이스에서 호스트로 복사하는 것으로 구성되어 있음.
- 이 세가지는 서로 다른 리소스이기 때문에 실제로 동시에 사용할 수 있음.
- 지금까지 해왔던 것은 GPU로 복사하고 GPU에서 실행하고 다시 복사해왔음.
- 매번 이중 하나의 리소스만 사용해왔었음.
- 세가지를 모두 동시에 활용하면 하드웨어를 더 활용할 수 있음.
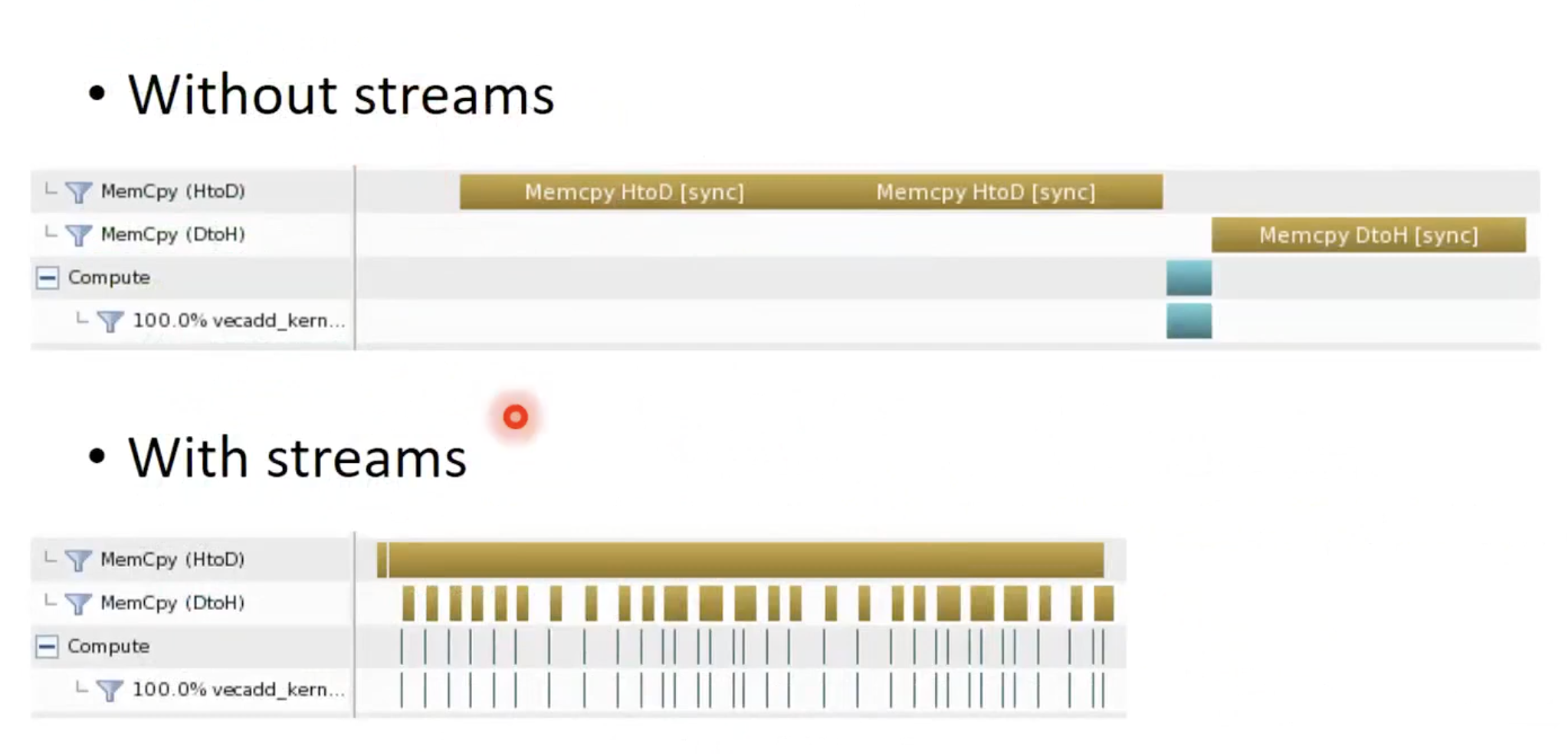
벡터 덧셈 utilization
Streams and Asynchronous Copies
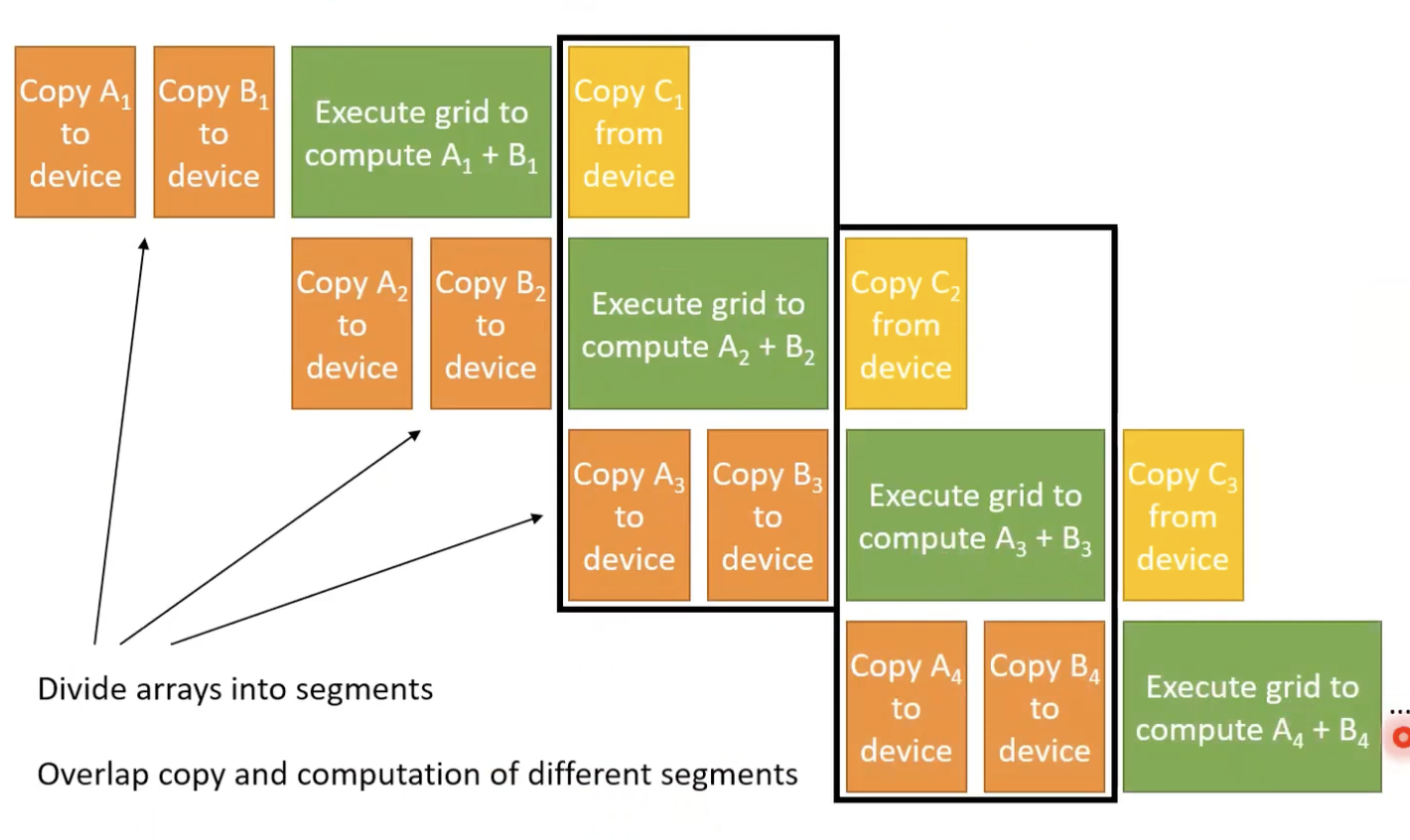
- 그리드와 메모리 복사 간의 병렬 처리는 스트림을 사용하여 달성할 수 있음 (비동기 복사도 사용해야 함)
- 다른 스트림에 작업을 넣는다면 병렬적으로 실행됨.
- 동일한 스트림 내의 작업은 직렬화됨.
- 스트림을 명시하지 않으면 default stream으로 추가됨.
- 호스트 실행과 메모리 복사를 동시에 이루어질 수 있도록 하려면 비동기 메모리 복사가 사용됨.
- 호스트가 복사가 완료될 때까지 기다리지 않고 다른 스트림에 있는 작업들을 진행할 수 있도록 함.
Using Streams and Asynchronous Copies
- stream 생성하기:
cudaError_t cudaStreamCreate(cudaStream_t* pStream)pStream: 생성된 스트림의 포인터
- stream내에서 비동기 복사:
cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count, cudaMemcpyKind kind, cudaStream_t stream=0);- cudaMemcpy와 비슷하지만 stream을 명시적으로 지정하기 위해 parameter가 추가됨.
- 특정 스트림에서의 grid 실행:
kernel<<< grid, block, smem, stream >>> (...)- 커널 실행에서의 4번째 configuration 인자로 들어감.
__global__ void vecadd_kernel(float* x, float* y, float* z, int N) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N) {
z[i] = x[i] + y[i];
}
}
void vecadd_gpu(float* x, float* y, float* z, int N) {
// Allocate GPU memory
float *x_d, *y_d, *z_d;
cudaMalloc((void**) &x_d, N * sizeof(float));
cudaMalloc((void**) &y_d, N * sizeof(float));
cudaMalloc((void**) &z_d, N * sizeof(float));
// Setup streams
unsigned int numStreams = 32;
cudaStream_t stream[numStreams];
for (unsigned int s = 0; s < numStreams; s++) {
cudaStreamCreate(&stream[s]);
}
// Stream the segments
unsigned int numSegments = numStreams;
unsigned int segmentSize = (N + numSegments - 1) / numSegments;
for (unsigned int s = 0; s < numSegments; s++) {
// Finding the segment bounds
unsigned int start = s * segmentSize;
unsigned int end = (start + segmentSize < N) ? start + segmentSize : N;
unsigned int Nsegment = end - start;
// Copy data to GPU
cudaMemcpyAsync(&x_d[start], &x[start], Nsegment * sizeof(float), cudaMemcpyHostToDevice, stream[s]);
cudaMemcpyAsync(&y_d[start], &y[start], Nsegment * sizeof(float), cudaMemcpyHostToDevice, stream[s]);
// Vector addition on GPU
int numThreadsPerBlock = 512;
int numBlocks = (Nsegment + numThreadsPerBlock - 1) / numThreadsPerBlock;
vecadd_kernel<<<numBlocks, numThreadsPerBlock, 0, stream[s]>>>(&x_d[start], &y_d[start], &z_d[start], Nsegment);
// Copy result back to host
cudaMemcpyAsync(&z[start], &z_d[start], Nsegment * sizeof(float), cudaMemcpyDeviceToHost, stream[s]);
}
cudaDeviceSynchronize();
// Free GPU memory
cudaFree(x_d);
cudaFree(y_d);
cudaFree(z_d);
}