pmpp lecture 22 dynamic parallelism 정리
Source: Lecture 22 - Dynamic Parallelism
Dynamic Parallelism
- 동적 병렬 처리는 GPU에서 실행 중인 스레드가 새로운 그리드를 실행할 수 있는 기능임.
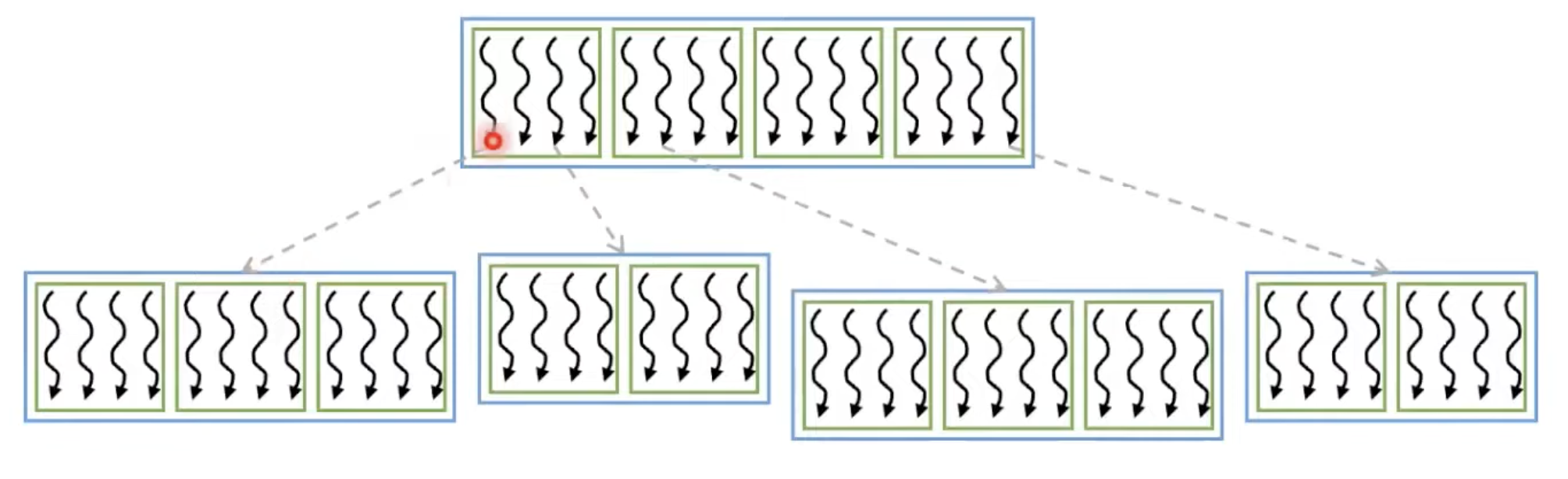
Nested Parallelism
병렬 처리가 있고, 각 병렬 처리 단위 내에서 더 많은 병렬 처리가 있을 때 유용함.
각 스레드가 실행하면서 병렬화 할 수 있는 더 많은 작업을 발견하는 경우, 즉 중첩된 병렬성을 가진 프로그래밍을 할 때 유용함.
중첩된 작업의 양을 알 수 없을 때 더욱 유용함. 고정된 양을 미리 실행하는 것이 어렵기 때문에.
Applications of Dynamic Parallelism
- 중첩 병렬 처리의 양을 알 수 없는 두가지 주요 이유가 있음.
- 중첩된 병렬 작업이 불규칙한 경우(스레드마다 다름)
- 예시로는 그래프 알고리즘이 있음. 각 vertex마다 다른 수의 이웃이 있음.
- 다른 예시로는 베지어 곡선이 있음. 점을 이용하여 선을 그리는 작업임.
- 선들을 그리기위해 선의 곡률에 따라 선을 그리는데 필요한 점의 수가 달라질 수 있음.
- 중첩된 병렬 작업이 재기적인 경우(알수 없는 깊이를 가짐), 스레드마다 재귀를 할수도 있고 안할 수 도 있음.
- tree traversal alogithm
- 분할 정복 알고리즘(퀵소트) - 더 나눠야 할지 말지 정해지지 않음.
- 중첩된 병렬 작업이 불규칙한 경우(스레드마다 다름)
Dynamic Parallelism API
- 커널을 호출하여 그리드를 실행하는 장치 코드는 호스트 코드와 동일함.
- 많은 스레드들이 있기 때문에 모든 실행이 동시에 실행될 수 는 없음. 따라서 장치는 이러한 실행을 위한 상태를 실행할 차례가 될때까지 버퍼에 저장 해야함.
- 아직 실행되지 않은 그리드 launch를 버퍼링하려면 메모리가 필요함.
- 메모리 제한이 있기 때문에 제공할 시작 횟수에 대한 실제로 제한이 있음. 가질 수 있는 동적 실행의 수에 제한이 있음을 의미함.
- 동적 실행 횟수의 제한은 보류 중인 실행 수(pending launch count)라고 함.
- 기본적으로, 런타임은 2048개의 그리드를 동적으로 실행할 수 있게 지원하고 제한을 넘으면 에러를 일으킴.
- 2048개 이상의 실행이 필요하면 제한을 늘려 런타임에 더 많은 메모리를 할당하도록 지시할 수 있음.
cudaDeviceSetLimit(cudaLimitDevRuntimePendingLaunchCount, < new limit >);- 2048개만해도 정상적인 상황은 아님. 이 제한을 늘리는 것은 어차피 하지 말아야할 일일 가능성이 높음.
프론티어를 사용한 BFS
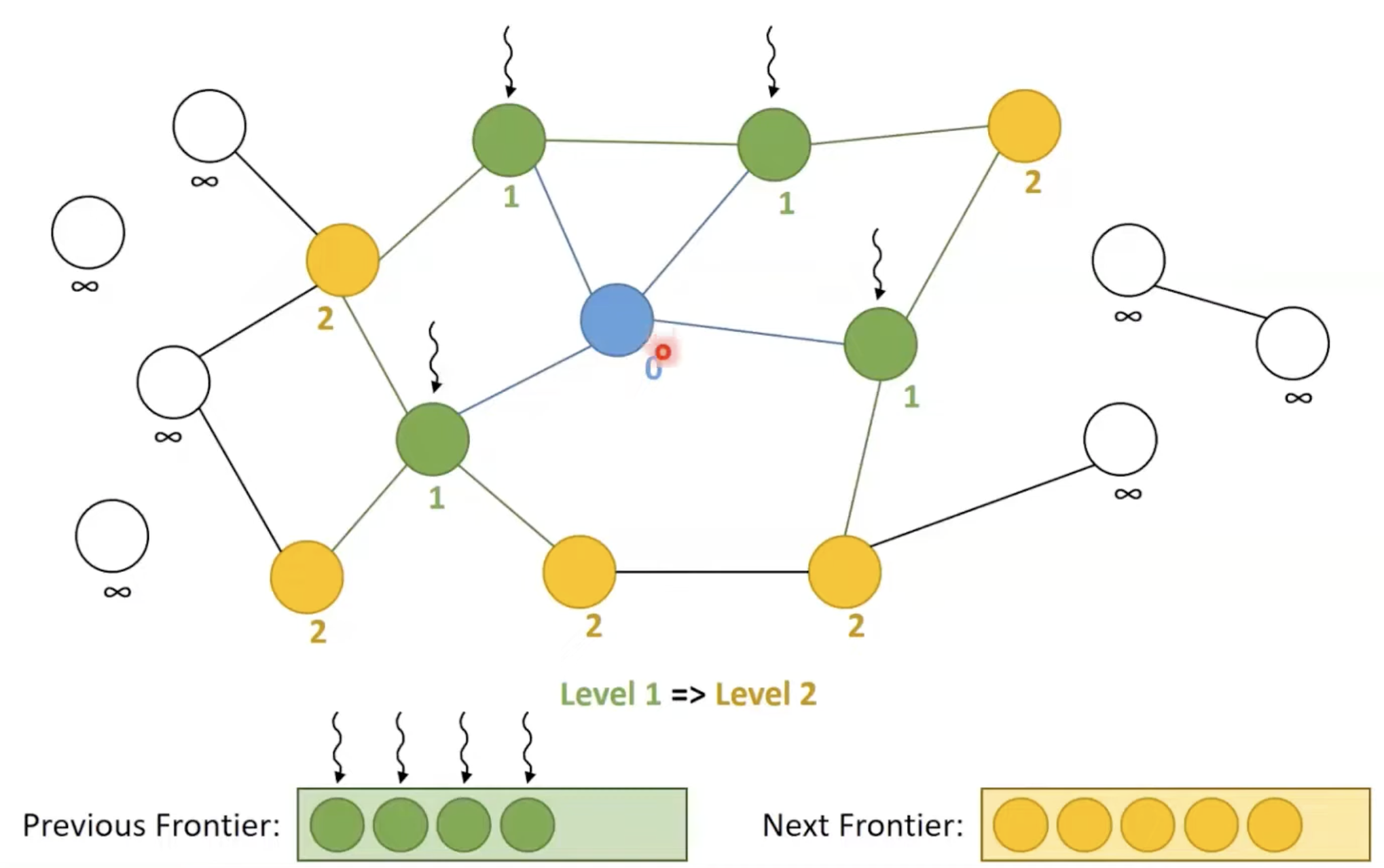
// 이웃의 수만큼 반복하는 대신 각 이웃에 대해 스레드를 실행할 것
__global__ void bfs_child_kernel(CSRGraph, csrGraph, unsigned int* level, unsigned int* currFrontier, unsigned int numPrevFrontier, unsigned int* numCurrFrontier, unsigned int currLevel, unsigned int numNeighbors, unsigned int start) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < numNeighbors) {
unsigned int edge = start + i;
unsigned int neighbor = csrGraph.dst[edge];
if (atomicCAS(&level[neighbor], UINT_MAX, currLevel) == UINT_MAX) { // 다른 스레드에서 동일한 정점에 대해 방문했을 경우
unsigned int currFrontierIdx = atomicAdd(numCurrFrontier, 1);
currFrontier[currFrontierIdx] = neighbor;
}
}
}
__global__ void bfs_kernel(CSRGraph, csrGraph, unsigned int* level, unsigned int* prevFrontier, unsigned int* currFrontier, unsigned int numPrevFrontier, unsigned int* numCurrFrontier, unsigned int currLevel) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < numPrevFrontier) {
unsigned int vertex = prevFrontier[i];
unsigned int start = csrGraph.srcPtrs[vertex];
unsigned int numNeighbors = csrGraph.srcPtrs[vertex + 1] - start;
unsigned int numThreadsPerBloc = 1024;
unsigned int numBlocks = (numNeighbors + numThreadsPerBloc - 1) / numThreadsPerBloc;
bfs_child_kernel<<< numBlocks, numThreadsPerBloc >>>(csrGraph, level, currFrontier, numPrevFrontier, numCurrFrontier, currLevel, numNeighbors, start);
}
}
void bfs_levels(CSRGraph, csrGraph, unsigned int* level, unsigned int* prevFrontier, unsigned int* currFrontier, unsigned int* numCurrFrontier) {
unsigned int numPrevFrontier = 1;
unsigned int numThreadsPerBlock = 256;
cudaDeviceSetLimit(cudaLimitDevRuntimePendingLaunchCount, csrGraph.numVertices);
for (unsigned int currLevel = 1; numPrevFrontier > 0; currLevel++) {
// Visit vertices in previous frontier
cudaMemset(numCurrFrontier, 0, sizeof(unsigned int));
unsigned int numBlocks = (numPrevFrontier + numThreadsPerBlock - 1) / numThreadsPerBlock;
bfs_child_kernel<<< numBlocks, numThreadsPerBlock >>>(csrGraph, level, prevFrontier, currFrontier, numPrevFrontier, numCurrFrontier, currLevel);
cudaDeviceSynchronize();
// Swap buffers
unsigned int* temp = prevFrontier;
prevFrontier = currFrontier;
currFrontier = temp;
cudaMemcpy(&numPrevFrontier, numCurrFrontier, sizeof(unsigned int), cudaMemcpyDeviceToHost);
}
cudaDeviceSynchronize();
}
- 14.45ms -> 130.59ms 10x slower
- 그리드들 각각이 비교적 너무 작아서 오히려 성능을 방해함.
Streams
- 우리가 스트림을 지정하지 않으면 기본적으로 default stream에 들어감.
- 디바이스에서 실행될 때, 동일한 블록에 있는 스레드들은 같은 default stream을 공유함.
- 같은 블록에 있는 스레드들에 의한 실행은 직렬화됨.
- 기본 스트림을 사용하는 대신 스레드 별로 스트림을 사용하면 병렬화 할 수 있음.
Per-Thread Stream
- 각 스레드마다 다른 스트림을 생성하고 각 스레드가 자체 스트림으로 시작하게 함으로써 병렬성을 개선할 수 있음.
- 방식 1: host에서와 같이 stream API를 사용함.
- 방식 2: 컴파일러 플래그를 사용함
--default-stream per-thread
- 결과: 130.59ms -> 125.51ms 약간 개선됨. 실제로 성능을 제한하는 것이 다른것임을 생각할 수 있음.
Optimizationss
- 흔한 함정:
- 우리가 아주 작은 그리드를 실행하는 경우 오버헤드가 가치가 없을 것이다.(순차적으로 하는것이 효율적일 것)
- 너무 많은 그리드를 실행하면 GPU에서 큐 지연이 일어남.
- 최적화: 실행에 임계값을 적용함.
- 오버헤드를 감수할 만한 큰 그리드만 실행하고 나머지는 직렬화함.
- 그래프의 정점들의 차수가 어떻게 분포 되었느냐에 따라 임계값은 달라질 것.(튜닝 포인트)
- 적용 후 6.9ms로 대폭 개선됨 🚀
- 최적화: 실행을 집계하는 것 (aggregate launches) - 하나의 스레드가 여러 스레드의 작업을 수집하도록 하고 그들을 대신하여 단일 스레드를 실행함. - 꽤 복잡해서 논문이 있다고 함.
__global__ void bfs_kernel(CSRGraph, csrGraph, unsigned int* level, unsigned int* prevFrontier, unsigned int* currFrontier, unsigned int numPrevFrontier, unsigned int* numCurrFrontier, unsigned int currLevel) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < numPrevFrontier) {
unsigned int vertex = prevFrontier[i];
unsigned int start = csrGraph.srcPtrs[vertex];
unsigned int numNeighbors = csrGraph.srcPtrs[vertex + 1] - start;
// 임계값을 넘으면 그리드를 실행하고 그렇지 않으면 직렬화함.
if (numNeighbors > 1200) {
unsigned int numThreadsPerBloc = 1024;
unsigned int numBlocks = (numNeighbors + numThreadsPerBloc - 1) / numThreadsPerBloc;
bfs_child_kernel<<< numBlocks, numThreadsPerBloc >>>(csrGraph, level, currFrontier, numPrevFrontier, numCurrFrontier, currLevel, numNeighbors, start);
} else {
for (unsigned int i = 0; i < numNeighbors; i++) {
unsigned int edge = start + i;
unsigned int neighbor = csrGraph.dst[edge];
if (atomicCAS(&level[neighbor], UINT_MAX, currLevel) == UINT_MAX) { // 다른 스레드에서 동일한 정점에 대해 방문했을 경우
unsigned int currFrontierIdx = atomicAdd(numCurrFrontier, 1);
currFrontier[currFrontierIdx] = neighbor;
}
}
}
}
}
Offloading Driver Code
- 여기서 Driver Code란, 장치드라이버가 아니고 기본적으로 전체 계산을 구동하는 함수를 뜻함.
- 어떤 어플리케이션에서는 계산을 구동하는 호스트 코드가 실행간에 스레드들을 동기화 하기 위해서 여러개의 연속적인 그리들 실행한다.
- BFS도 다음 레벨로 넘어가기 전에 이전 레벨의 작업을 완료해야 함.
- 동적병렬처리의 또 다른 응용은 이 드라이버 코드를 디바이스로 오프로드하는 것.
- 주요 장점은 호스트가 다른 일을 할 수 있게 해주는 것임.
- 실제로 성능 향상을 기대하기는 어려움. 하지만 CPU를 확보할 수 있음.
__global__ void bfs_levels_kernel(CSRGraph, csrGraph, unsigned int* level, unsigned int* prevFrontier, unsigned int* currFrontier, unsigned int* numCurrFrontier) {
unsigned int numPrevFrontier = 1;
unsigned int numThreadsPerBlock = 256;
for (unsigned int currLevel = 1; numPrevFrontier > 0; currLevel++) {
// Visit vertices in previous frontier
*numCurrFrontier = 0;
unsigned int numBlocks = (numPrevFrontier + numThreadsPerBlock - 1) / numThreadsPerBlock;
bfs_child_kernel<<< numBlocks, numThreadsPerBlock >>>(csrGraph, level, prevFrontier, currFrontier, numPrevFrontier, numCurrFrontier, currLevel);
cudaDeviceSynchronize();
// Swap buffers
unsigned int* temp = prevFrontier;
prevFrontier = currFrontier;
currFrontier = temp;
numPrevFrontier = *numCurrFrontier;
}
}
void bfs_levels(CSRGraph, csrGraph, unsigned int* level, unsigned int* prevFrontier, unsigned int* currFrontier, unsigned int* numCurrFrontier) {
cudaDeviceSetLimit(cudaLimitDevRuntimePendingLaunchCount, csrGraph.numVertices);
bfs_levels_kernel<<< 1, 1 >>>(csrGraph, level, prevFrontier, currFrontier, numCurrFrontier);
cudaDeviceSynchronize();
}
Memory Visibility
- 부모 스레드가 글로벌 메모리에 쓰고 실행을 수행하면 자식 그리드의 스레드는 전역 메모리의 변경사항을 볼 수 있음.
- 그리드의 자식 스레드에 의해 수행되는 작업은 자식이 돌아오고 부모가 동기화된 후 부모에게 보일 것임.
- 스레드의 로컬 메모리와 블록의 공유 메모리는 자식 스레드가 접근할 수 없음.
- 부모가 시작한 자식 스레드가 다른 SM 에서 실행 될 수 있기 때문에
중첩 깊이 (Nesting Depth)
- 중첩 깊이는 동적 실행 그리드들이 얼마나 깊게 실행 되었는지에 대한 값임.
- 하드웨어에 의해 제한이 있으며 일반적으로 24임.